Puedes leer el artículo anterior de la serie aquí: mecanismos de replicación
Es hora de que hablemos sobre una propiedad importante de la replicación del mundo real: el retraso de replicación.
En el primer artículo de la serie, mencionamos que hay dos formas de replicación: síncrona y asíncrona. La replicación síncrona espera hasta que cada seguidor ha aplicado los cambios antes de enviar el mensaje de solicitud exitosa de vuelta a los usuarios. La replicación asíncrona, por otro lado, continúa como de costumbre después de notificar a los seguidores de los cambios, incluso si no los han aplicado aún.
También mencionamos que la mayoría de sistemas de producción usan replicación asíncrona. El riesgo de perder todo el sistema si una réplica falla hace que la replicación síncrona sea demasiado arriesgada para la mayoría de proyectos. A pesar de las ventajas obvias, con la elección de replicación asíncrona viene el desafío del retraso de replicación.
Este retraso sucede porque los seguidores no pueden mantenerse al día con los cambios y se quedan atrás del líder por algunos segundos. Si la carga es mayor de lo esperado o hay un problema de red, los seguidores pueden retrasarse incluso por varios minutos. Como imaginas, el problema principal es que la mayoría de usuarios no están contentos con ser servidos con datos viejos.
Si esperas suficiente tiempo los seguidores eventualmente se pondrán al día con el líder y empezarán a servir resultados actualizados. Esto se conoce como consistencia eventual, o la garantía de que los seguidores eventualmente se volverán consistentes con la versión más reciente de los datos.
El retraso de replicación existe e incluso si raramente va más allá de algunos milisegundos, conocer las implicaciones es importante. Asumir que tu replicación sucede instantáneamente e ignorar el retraso es una fuente garantizada de problemas en el futuro de tu proyecto.
Echemos un vistazo a algunas de las anomalías más comunes asociadas con el retraso de replicación y algunas maneras de lidiar con ellas.
3 Anomalías causadas por retraso de replicación y 3 garantías
1 - Poder leer tus propias escrituras
Supón que estás escribiendo una publicación en un foro. Pasas tiempo creando una buena respuesta y luego presionas enviar, la página se actualiza y luego … nada, no puedes ver la publicación que acabas de enviar. Esto puede suceder si lees datos de una réplica retrasada inmediatamente después de enviar tu publicación.
La réplica líder recibió tu escritura y la reenvió a cada seguidor, pero todavía no han aplicado los cambios. Asumirás que tu envío se perdió y te sentirás bastante molesto por ello. Incluso podrías tratar de escribir y enviar la misma publicación una segunda vez.
La consistencia de leer-tus-propias-escrituras es la garantía de que si el usuario recarga la página, siempre verá las actualizaciones que acaba de enviar. Es importante notar que esta garantía solo aplica a tus propias escrituras y no a las de otros usuarios. El objetivo es permitir que los usuarios sepan que sus cambios fueron enviados exitosamente.
Hay muchas maneras de ofrecer esta garantía:
- Todo lo que el usuario puede cambiar debe ser leído desde el líder: Recuerda que el líder es la única réplica garantizada de tener la versión más reciente de los datos. También hay algunas partes de la aplicación que solo tú puedes modificar, como tu configuración y publicaciones propias. Si el usuario solicita algunos de estos datos pueden ser servidos por el líder para garantizar que obtienes la versión más reciente. Nota que esto solo funciona si el usuario puede modificar solo partes específicas de la aplicación y sabes exactamente cuáles son.
- Servir lecturas desde el líder por una ventana de tiempo específica: Otro enfoque es mantener un temporizador en el cliente que empieza a correr después de que el usuario realiza una escritura. Por una cantidad específica de tiempo (2 minutos, por ejemplo) todas las lecturas serán servidas por el líder. Después de esa ventana de tiempo, se asume que todos los seguidores se pusieron al día y las lecturas pueden ser servidas por ellos.
- Etiquetar con tiempo las solicitudes de lectura: Una versión más elaborada de la segunda opción es hacer que el cliente recuerde el tiempo específico de la última escritura enviada. Esta etiqueta de tiempo se envía junto con cada solicitud de lectura y el sistema asegura que solo seguidores que tienen datos hasta ese punto pueden servir las lecturas. Esto puede ser difícil de implementar, especialmente si los mismos usuarios están enviando solicitudes desde diferentes clientes.
2 - Moverse hacia atrás en el tiempo
Esto puede suceder cuando las lecturas son reenviadas aleatoriamente a diferentes réplicas.
Supón que abres un hilo de foro y empiezas a leer. Tu solicitud de lectura es reenviada a un seguidor actualizado y obtienes tus resultados. Siguiente, presionas actualizar para cargar más comentarios, pero esta vez la lectura es reenviada a una réplica retrasada. Tu navegador renderiza la página, pero ahora tiene menos comentarios que antes. El síntoma principal de esta anomalía es que el usuario siente como si la aplicación se moviera hacia atrás en el tiempo.
Esto es especialmente molesto porque nuestra primera solicitud devolvió resultados actualizados, y ahora solo tenemos datos viejos.
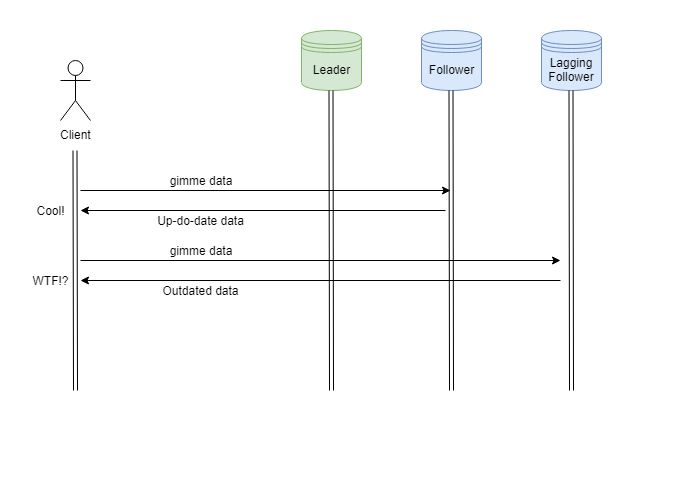
Lecturas monótonas es la garantía de que un usuario no puede leer datos más viejos después de leer datos más nuevos. Diferentes sistemas implementan esta garantía de diferentes maneras, pero la forma más simple de lograrlo es asegurando que cada usuario siempre lee de la misma réplica.
3 - Violación de causalidad
A veces hay un orden causal establecido entre dos o más datos. Este es el caso de los comentarios en un hilo de foro, donde el orden de los comentarios sigue el orden en el que fueron publicados. Leer los comentarios en el orden incorrecto puede hacer la tarea de entender la conversación difícil o imposible.
Este es un problema con sistemas fragmentados donde los datos están distribuidos entre diferentes bases de datos. Estas bases de datos operan independientemente y no hay un orden global impuesto en las escrituras. En estos sistemas, los usuarios podrían leer algunas partes de los datos de bases de datos desactualizadas y otras partes de BDs más nuevas, resultando en escenarios como el que acabamos de describir.
Lecturas de prefijo consistente es una garantía que previene este tipo de problema. Asegura que si una secuencia de escrituras sucede en un orden específico al leer en el futuro aparecerán en ese orden. Hay diferentes mecanismos para imponer esta garantía, como escribir a la misma partición todas las escrituras que están relacionadas, o usar algoritmos que mantienen seguimiento de las dependencias causales.
Soluciones
Ok, pero ¿cómo debería manejar estos problemas?
Como se mencionó arriba, a veces no necesitas hacerlo. Si el comportamiento de tu aplicación es aceptable incluso con varios minutos de retraso de replicación, ¡entonces eso es genial!
Si tu sistema (o usuarios) no pueden tolerar esto, necesitarás imponer estas garantías por el bien de una buena experiencia de usuario. Muchos vendedores ofrecen estas garantías como características configurables en sus sistemas. Lo más importante de recordar es que pretender que tu replicación es síncrona cuando no lo es no te ayudará con los problemas.
Bueno, llegamos al final de esta serie, y espero que hayas aprendido una o dos cosas útiles. Este es un tema masivo, y solo cubrimos algunos conceptos fundamentales en una forma de replicación: replicación líder/seguidor. Hay otras formas de replicación con múltiples líderes o sin líderes en absoluto. La situación se vuelve aún más interesante con la introducción de fragmentación: distribuir la información de una base de datos en múltiples máquinas. Esto, como imaginaste, es otro tema enorme con muchos conceptos interesantes y casos límite.
Espero que esta serie te haya ayudado a decidir si los sistemas distribuidos es un tema en el que quieres profundizar más. La importancia de la replicación en aplicaciones modernas no puede ser subestimada. Probablemente uses varios de estos sistemas diariamente: aplicaciones de redes sociales, software de productividad y control de versiones entre otros. Ahora cuando escuches sobre réplicas, seguidores y retraso de replicación sabrás de qué están hablando.
¡Gracias por leer!
Qué hacer después:
- Comparte este artículo con amigos y colegas. Gracias por ayudarme a llegar a personas que podrían encontrar útil esta información.
- Esta serie está basada en Designing Data-Intensive Applications, asegúrate de echar un vistazo a los capítulos 5 y 6 para una explicación más profunda de replicación y fragmentación.
- Envíame un email con preguntas, comentarios o sugerencias (está en la página Autor)