El código fuente para este artículo se puede encontrar aquí.
¡Bienvenido a otro experimento en la nube! La idea detrás de estos tutoriales prácticos es proporcionar experiencia práctica construyendo soluciones nativas de la nube de diferentes tamaños usando servicios de AWS y CDK. Nos enfocaremos en desarrollar experiencia en Infraestructura como Código, servicios de AWS, y arquitectura de la nube mientras entendemos tanto el “cómo” como el “por qué” detrás de nuestras decisiones.
Una Interfaz Única
Me gustan los monolitos. Son fáciles de empaquetar y desplegar, y cuando usas buenos patrones arquitectónicos y principios de diseño, también son fáciles de entender y mantener.
También sé que para muchos escenarios, un monolito probablemente no sea la mejor opción. Algunos casos se benefician más de arquitecturas que usan un enfoque más granular—ya sea microservicios, serverless, o incluso una combinación de ambos. Estas soluciones a menudo se benefician también de proporcionar un único punto de entrada para todos los servicios que componen la aplicación.
La principal ventaja de este enfoque es que desde la perspectiva de las entidades que usan tu servicio, hay una interfaz bien definida en la que pueden confiar. Esta capa actúa como un límite protector que aísla tu backend y te otorga la flexibilidad de dividir la funcionalidad como mejor te parezca.
En este laboratorio, vamos a aprender cómo ocultar los detalles de implementación de nuestro backend detrás de una sola entidad: un API Gateway. Esto es lo que construiremos:
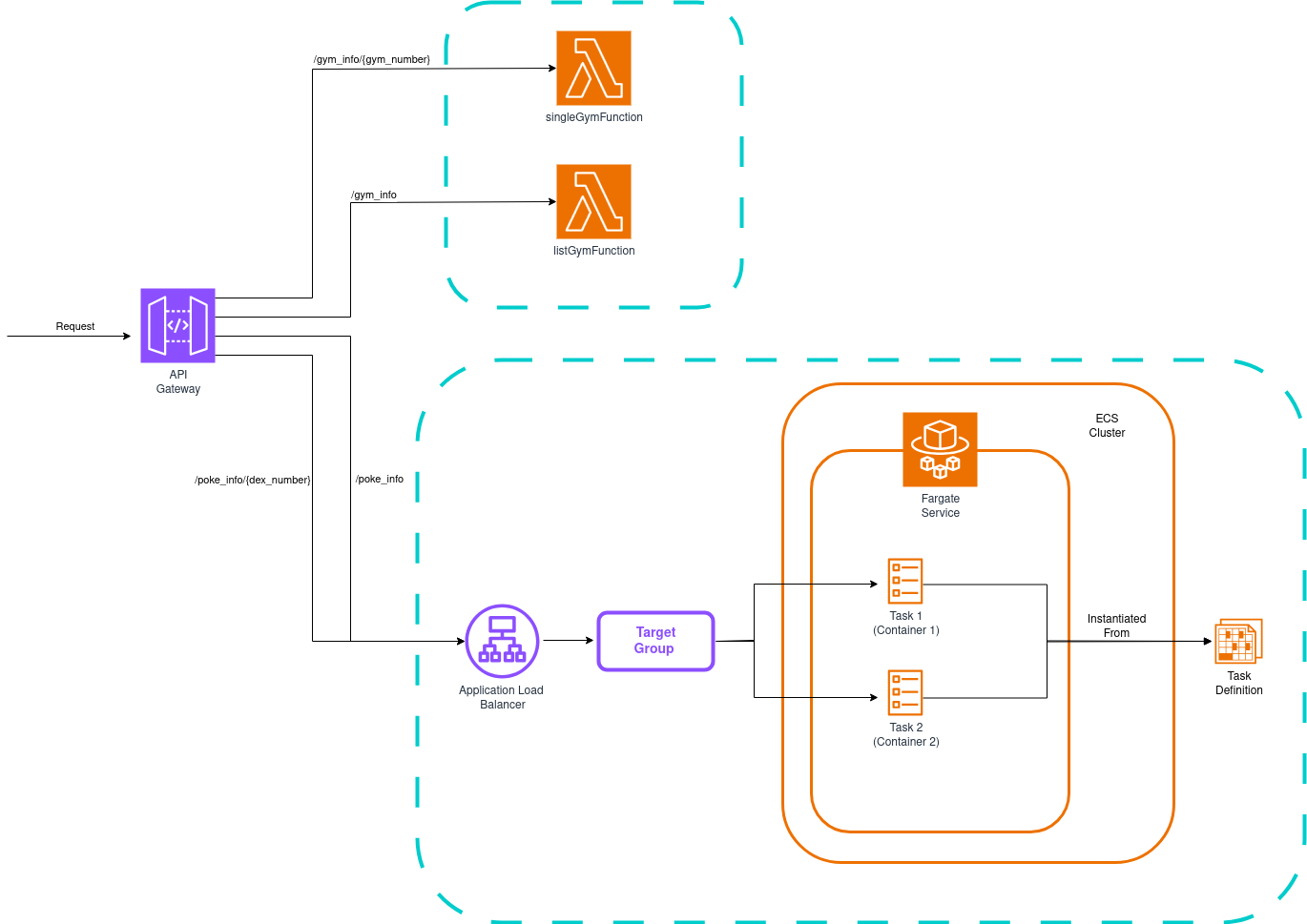
Proporcionaremos una API que devuelve datos sobre la primera generación de juegos de Pokémon, implementando estas acciones:
- /gym_info: Devuelve información sobre todos los gimnasios originales
- /gym_info/{gym_number}: Consulta datos para un gimnasio específico
- /poke_info: Devuelve información sobre todos los Pokémon de 1ra generación
- /poke_info/{dex_number}: Consulta datos para un Pokémon específico
Los endpoints de gimnasios serán manejados por funciones Lambda, mientras que los endpoints de Pokémon serán servidos por un cluster ECS con balanceador de carga ejecutándose en Fargate. El API Gateway enrutará las peticiones a los recursos de cómputo apropiados. ¡Una buena mezcla de lambdas y contenedores!
¡Empecemos!
Escribiendo el Backend
Funciones Lambda
Necesitaremos dos funciones Lambda para proporcionar datos para las rutas /gym_info y /gym_info/{gym_number}. Las escribiremos en Python:
Para gym_list.py:
import logging
import json
logger = logging.getLogger()
logger.setLevel("INFO")
with open('gym_data.json', 'r') as file:
gym_data = json.load(file)
def handler(event, context):
logger.info("Serving request for all gyms")
return {
'statusCode': 200,
'headers': {'content-type': 'application/json'},
'body': json.dumps(gym_data)
}
Y para gym.py:
import logging
import json
logger = logging.getLogger()
logger.setLevel("INFO")
with open('gym_data.json', 'r') as file:
gym_data = json.load(file)
def handler(event, context):
gym_number = event.get('pathParameters', {}).get('gym_number', '')
logger.info(f"Serving request for gym#{gym_number}")
return {
'statusCode': 200,
'headers': {'content-type': 'application/json'},
'body': json.dumps(gym_data.get(gym_number, {}))
}
Estas son funciones simples que devuelven datos de un archivo JSON. Normalmente, usarías una base de datos para almacenar los datos, pero para este laboratorio, lo mantendremos simple.
La Aplicación de Datos de Pokémon
Necesitamos una aplicación que podamos contenerizar para probar nuestro stack y proporcionar datos para las rutas /poke_info y /poke_info/{dex_number}. Crearemos una pequeña aplicación Sinatra con tres rutas: las dos descritas anteriormente, más la raíz.
Crea una carpeta llamada app, y dentro de ella crea un Gemfile con estos contenidos:
source 'https://rubygems.org'
gem 'sinatra'
gem 'rackup'
gem 'puma'
Ahora crea el archivo principal de la aplicación. Al lado del Gemfile, crea app.rb:
# frozen_string_literal: true
require 'sinatra'
require 'json'
set :port, 4567
set :bind, '0.0.0.0'
POKE_DATA = JSON.load File.open 'pokedata.json'
before do
content_type :json
end
get '/' do
{
data: {status: 'All Good'},
source: ENV['HOSTNAME']
}
end
get '/poke_info' do
{
data: POKE_DATA,
source: ENV['HOSTNAME']
}
end
get '/poke_info/:dex_number' do
{
data: POKE_DATA[params[:dex_number]],
source: ENV['HOSTNAME']
}
end
after do
response.body = JSON.dump(response.body)
end
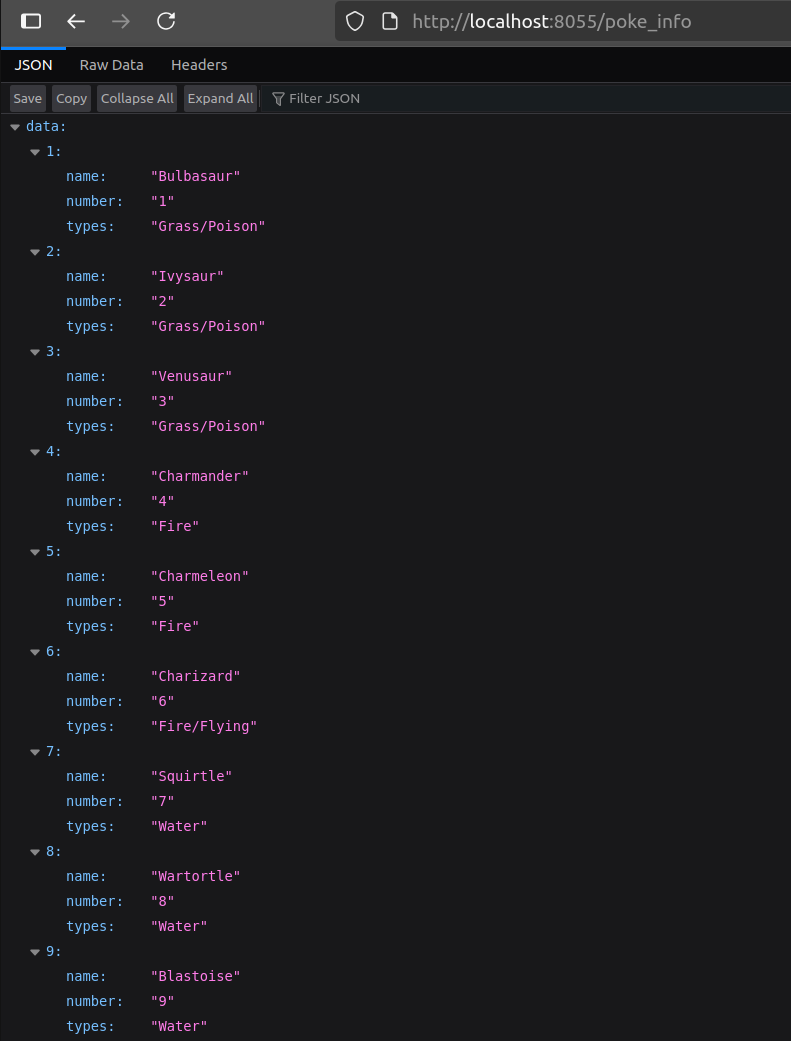
Como las funciones Lambda, esta aplicación simplemente devuelve datos de un archivo JSON. Incluimos un campo extra source para verificar que el balanceador de carga esté funcionando como se espera y que múltiples contenedores estén sirviendo peticiones.
Finalmente, escribe un Dockerfile para construir la imagen Docker de nuestra aplicación:
# Dockerfile
FROM ruby:3.3
ENV APP_ENV=production
WORKDIR /app
COPY . /app
RUN bundle install
EXPOSE 4567
CMD ["ruby", "app.rb"]
Puedes copiar la aplicación del repo del laboratorio si prefieres. Si quieres probarla localmente, ejecuta docker build --tag 'sample-sinatra' . para crear la imagen del contenedor, luego docker run -p 8055:4567 sample-sinatra. Esto servirá la aplicación en localhost en el puerto 8055:
Construyendo Nuestro Stack
Creación del Proyecto
Primero, necesitamos nuestra configuración regular del proyecto.
Crea una carpeta vacía (la mía se llama APIGatewayPattern) y ejecuta cdk init app --language typescript dentro de ella.
Este próximo cambio es opcional, pero lo primero que hago después de crear un nuevo proyecto CDK es navegar a la carpeta bin y renombrar el archivo de la aplicación a main.ts. Luego abro cdk.json y edito la configuración app:
{
"app": "npx ts-node --prefer-ts-exts bin/main.ts",
"watch": {
...
}
}
Ahora tu proyecto reconocerá main.ts como el archivo principal de la aplicación. No tienes que hacer esto—simplemente me gusta tener un archivo llamado main como punto de entrada.
Creando el Stack Base
Delegaremos la creación de recursos de cómputo a constructos personalizados. El stack principal creará el API Gateway e instanciará cada constructo. Los cuadrados azules en el diagrama representan los contenidos de cada constructo personalizado.
Nuestro stack principal es extremadamente simple:
import * as cdk from 'aws-cdk-lib';
import { Construct } from 'constructs';
import { aws_apigatewayv2 as gateway } from "aws-cdk-lib";
import { GymAPIConstruct } from "../constructs/gym_api";
import { PokeAPIConstruct } from "../constructs/poke_api";
export class ApiGatewayPatternStack extends cdk.Stack {
constructor(scope: Construct, id: string, props?: cdk.StackProps) {
super(scope, id, props);
const myApi = new gateway.HttpApi(this, "myApi");
const gymAPI = new GymAPIConstruct(this, "gymApi", { httpApiGateway: myApi });
const pokeAPI = new PokeAPIConstruct(this, "pokeApi", { httpApiGateway: myApi });
new cdk.CfnOutput(this, "APIEndpoint", { value: myApi.apiEndpoint });
}
}
El API Gateway se pasa como parámetro a cada constructo. Cada constructo crea los recursos que necesita y los conecta para que el API Gateway pueda enrutar peticiones a la entidad de cómputo apropiada.
La línea final crea un output con el endpoint del API Gateway, para que puedas probarlo inmediatamente después del despliegue.
Creando el Constructo Basado en Lambda
Para ahora, deberías tener una carpeta lambdas al mismo nivel que bin y lib. Dentro de ella, coloca tus archivos gym_list.py y gym.py. Crea una carpeta constructs y dentro de ella, crea gym_api.ts:
import { Construct } from 'constructs';
import { aws_apigatewayv2 as gateway } from "aws-cdk-lib";
import { aws_apigatewayv2_integrations as api_integrations } from "aws-cdk-lib";
import { aws_lambda as lambda } from "aws-cdk-lib";
export interface GymAPIConstructProps {
httpApiGateway: gateway.HttpApi;
}
export class GymAPIConstruct extends Construct {
constructor(scope: Construct, id: string, props: GymAPIConstructProps) {
super(scope, id);
const myApi = props.httpApiGateway;
const singleGymFunction = new lambda.Function(this, "sgLambda", {
runtime: lambda.Runtime.PYTHON_3_13,
code: lambda.Code.fromAsset("lambdas"),
handler: "gym.handler",
description: `Provides a single gym for the ${myApi.httpApiName} API`,
});
const listGymFunction = new lambda.Function(this, "lgLambda", {
runtime: lambda.Runtime.PYTHON_3_13,
code: lambda.Code.fromAsset("lambdas"),
handler: "gym_list.handler",
description: `Provides a list of gyms for the ${myApi.httpApiName} API`,
});
myApi.addRoutes({
path: "/gym_info/{gym_number}",
methods: [gateway.HttpMethod.GET],
integration: new api_integrations.HttpLambdaIntegration(
"sgIntegration",
singleGymFunction
)
});
myApi.addRoutes({
path: "/gym_info",
methods: [gateway.HttpMethod.GET],
integration: new api_integrations.HttpLambdaIntegration(
"lgIntegration",
listGymFunction
)
});
}
}
Notemos los aspectos más interesantes de este código:
- Definimos props personalizados para este constructo a través de
GymAPIConstructProps—el único prop necesario es el API Gateway - Creamos dos funciones Lambda, una para cada ruta
- Agregamos ambas funciones Lambda al API Gateway usando el método
addRoutes - Pasamos las funciones Lambda al constructo
HttpLambdaIntegration, que crea la integración entre el API Gateway y Lambda
El procedimiento es similar a lo que hemos hecho en otros experimentos, así que no hay nada que no hayamos visto antes. ¡La parte importante es que ahora estamos organizando esta funcionalidad en un constructo personalizado!
Creando el Constructo Basado en ECS
Crea poke_api.ts en la carpeta constructs:
import { Construct } from 'constructs';
import { aws_apigatewayv2 as gateway, aws_apigatewayv2_integrations as api_integrations } from "aws-cdk-lib";
import { aws_ecs as ecs } from "aws-cdk-lib";
import { aws_ec2 as ec2 } from "aws-cdk-lib";
import { aws_ecs_patterns as ecs_patterns } from "aws-cdk-lib";
export interface PokeAPIConstructProps {
httpApiGateway: gateway.HttpApi;
}
export class PokeAPIConstruct extends Construct {
constructor(scope: Construct, id: string, props: PokeAPIConstructProps) {
super(scope, id);
const myApi = props.httpApiGateway;
const fargateService = new ecs_patterns.ApplicationLoadBalancedFargateService(
this,
"fargateService",
{
taskImageOptions: {
image: ecs.ContainerImage.fromAsset('app'),
containerPort: 4567,
},
desiredCount: 2,
memoryLimitMiB: 1024,
minHealthyPercent: 100,
}
);
const vpcLinkSecurityGroup = new ec2.SecurityGroup(this, "vpcLinkSecurityGroup", {
vpc: fargateService.cluster.vpc,
allowAllOutbound: true,
});
vpcLinkSecurityGroup.connections.allowFrom(ec2.Peer.anyIpv4(), ec2.Port.tcp(80));
vpcLinkSecurityGroup.connections.allowFrom(ec2.Peer.anyIpv4(), ec2.Port.tcp(443));
const vpcLink = new gateway.VpcLink(this, "myVpcLink", {
vpc: fargateService.cluster.vpc,
subnets: {
subnetType: ec2.SubnetType.PRIVATE_WITH_EGRESS
},
securityGroups: [vpcLinkSecurityGroup]
});
myApi.addRoutes({
path: "/poke_info/{dex_number}",
methods: [gateway.HttpMethod.GET],
integration: new api_integrations.HttpAlbIntegration(
"spIntegration",
fargateService.listener,
{
vpcLink: vpcLink
}
)
});
myApi.addRoutes({
path: "/poke_info",
methods: [gateway.HttpMethod.GET],
integration: new api_integrations.HttpAlbIntegration(
"lpIntegration",
fargateService.listener,
{
vpcLink: vpcLink
}
)
});
}
}
Este constructo es un poco más complejo, así que discutamos los aspectos clave:
- Creamos la mayoría de los recursos usando el constructo
ApplicationLoadBalancedFargateService. Si quieres aprender más sobre cómo funciona, echa un vistazo a este laboratorio y este laboratorio donde implementamos lo mismo desde cero - Agregamos rutas a nuestro API Gateway y usamos
HttpAlbIntegrationpara integrarlo con el cluster ECS. Nota que pasamos el listener, no el servicio Fargate en sí - El aspecto más crítico es el
VpcLinkque creamos. Este recurso permite al API Gateway conectarse al cluster ECS. Normalmente,HttpAlbIntegrationcreará un VPC link automáticamente, pero crea uno sin un security group que permita acceso al cluster. La solución es crear nuestro propio VPC link, asociarlo con un security group que tenga la configuración de acceso correcta, y pasarlo al constructor deHttpAlbIntegration
¡Con este paso, estamos listos para desplegar nuestro stack!
Probando la Solución
Después de ejecutar cdk deploy y esperar a que termine el despliegue, obtendrás la URL del API Gateway en el output. La mía se veía así:
ApiGatewayPatternStack.APIEndpoint = https://8z5zmq5egj.execute-api.eu-west-1.amazonaws.com
Prueba la API con estos comandos:
curl -X GET 'https://<API_ENDPOINT>/gym_info'
curl -X GET 'https://<API_ENDPOINT>/gym_info/4'
curl -X GET 'https://<API_ENDPOINT>/poke_info'
curl -X GET 'https://<API_ENDPOINT>/poke_info/93'
Recuerda reemplazar <API_ENDPOINT> con tu endpoint real.
¡IMPORTANTE! Siempre recuerda eliminar tu stack ejecutando cdk destroy o eliminándolo manualmente en la consola.
Mejoras y Experimentos
- Escribe tus propias adiciones a la API. Por ejemplo, implementa un constructo que cree un cluster ECS ejecutándose en EC2 y sirva datos sobre uno de tus hobbies
- Nota que no agregamos la ruta raíz de la aplicación al API Gateway. ¿Es posible agregar rutas comodín (
poke_info*)? ¿Sería esto una buena o mala idea, y por qué? - Usa este experimento como plantilla para construir tu propia API usando una variedad de diferentes backends para cómputo
- ¿Sería posible tener una configuración similar sin el balanceador de carga? ¿Cómo apuntarías al cluster directamente? ¿Sería eso una buena idea?
- Nota que estamos pasando el API Gateway a los constructos personalizados y delegando la tarea de agregar rutas a cada constructo. ¿En qué escenarios es beneficioso este enfoque, y cuándo podría ser problemático?
Establecer límites entre diferentes partes de tu solución es una buena práctica y ayuda a mantener tu arquitectura limpia y mantenible. Esta forma de ocultamiento de información es útil tanto a pequeña escala (como al definir la interfaz pública de una clase) como a gran escala (como al definir la interfaz pública de una flota de microservicios).
Es interesante cómo algunas ideas son aplicables a distintos niveles, y espero que este laboratorio sirva para ilustrar este punto. Como siempre, siéntete libre de hacer tus propias modificaciones y experimentos—¡es la mejor manera de aprender!
¡Espero que encuentres esto útil!