
You can read the previous article in the series here: replication mechanisms
It's time we talk about an important property of real-world replication: replication lag.
In the first article of the series, we mentioned that there are two forms of replication: synchronous and asynchronous. Synchronous replication waits until every follower has applied the changes before sending the successful request message back to the users. Asynchronous replication, on the other hand, continues business as usual after notifying the followers of the changes, even if they haven't applied them yet.
We also mentioned that most production systems use asynchronous replication. The risk of losing the whole system if a replica fails makes synchronous replication too risky for most projects. Despite the obvious advantages, with the choice of async replication comes the challenge of replication lag.
This lag happens because followers can't keep up with the changes and fall behind the leader for some seconds. If the load is higher than expected or there is a network problem followers can lag behind even for several minutes. As you imagine, the main problem is that most users are not happy with be served old data.
If you wait enough time the followers will eventually catch up with the leader and start serving up-to-date results. This is known as eventual consistency, or the guarantee that followers will eventually become consistent with the latest version of data.
Replication lag exists and even if it rarely goes beyond some milliseconds, knowing the implications is important. Assuming that your replication happens instantaneously and ignoring the lag is a guaranteed source of problems in the future of your project.
Let's take a look at some of the most common anomalies associated with replication lag and some ways to deal with them.
3 Anomalies caused by replication lag and 3 guarantees
1 - Being able to read your own writes
Suppose you are writing a post in a forum. You spend time creating a good reply and then press submit, the page refreshes and then ... nothing, you can't see the post you have just submitted. This can happen if you read data from a lagging replica immediately after submitting your post.
The leader replica received your write and forwarded it to every follower, but they still haven't applied the changes. You will assume that your submission got lost and feel pretty upset about it. You might even try to write and submit the same post a second time.
The read-your-own-writes consistency is the guarantee that if the user reloads the page, they will always see the updates they just submitted. It's important to notice that this guarantee only applies to your own writes and not other users'. The goal is to let users know that their changes were successfully submitted.
There are many ways of offering this guarantee:
- Everything the user can change must be read from the leader: Remember that the leader is the only replica guaranteed to have the latest version of the data. There are also some parts of the application that only you can modify, like your settings and owned posts. If the user requests some of this data it can be served by the leader to guarantee you get the latest version. Note that this only works if the user can modify only specific parts of the application and you know exactly which ones.
- Serve reads from the leader for a specific time window: Another approach is to keep a timer in the client that starts running after the user performs a write. For a specific amount of time (2 minutes, for example) all reads will be served by the leader. After that time window, it's assumed that all followers caught up and reads can be served by them.
- Time-tag the read requests: A more elaborate version of the second option is to have the client remember the specific time of the last write sent. This time tag is sent alongside every read request and the system ensures that only followers that have data up to that point can serve the reads. This can be hard to implement, especially if the same users are sending request from different clients.
2 - Moving back in time
This can happen when reads are randomly forwarded to different replicas.
Suppose you open a forum thread and start reading. Your read request is forwarded to an up-to-date follower and you get your results. Next, you press refresh to load more comments, but this time the read is forwarded to a lagging replica. Your browser renders the page, but now it has fewer comments than before. The main symptom of this anomaly is that the user feels as if the application moves back in time.
This is especially annoying because our first request returned up-to-date results, and now we only have old data.
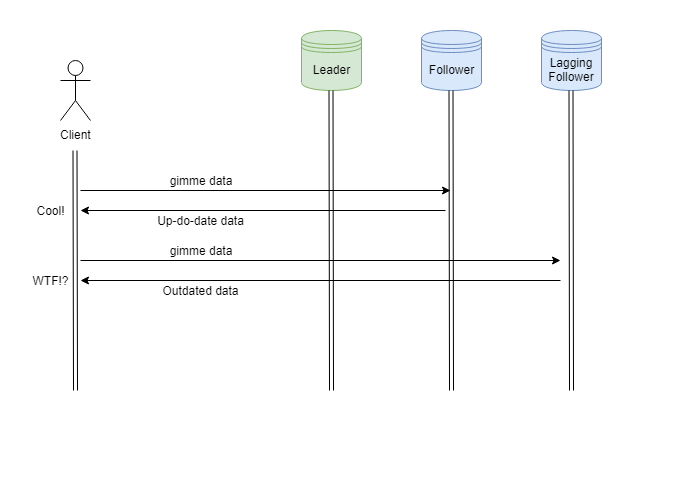
Monotonic reads is the guarantee that a user can't read older data after reading newer data. Different systems implement this guarantee in different ways, but the simplest way of achieving it is by ensuring that each user always reads from the same replica.
3 - Violation of causality
Sometimes there's an established causal order between two or more pieces of data. This is the case of comments in a forum thread, where the order of comments follow the order in which they were posted. Reading the comments in the wrong order can make the task of understanding the conversation difficult or impossible.
This is a problem with sharded systems where the data is distributed among different databases. These databases operate independently and there is no enforced global order in the writes. In these systems, users might read some parts of the data from outdated databases and other parts from newer DBS, resulting in scenarios like the one we just described.
Consistent prefix reads is a guarantee that prevents this type of problem. It ensures that if a sequence of writes happens in a specific order when reading in the future they will appear in that order. There are different mechanisms for enforcing this guarantee, like writing to the same partition all writes that are related, or using algorithms that keep track of causal dependencies.
Solutions
Ok, but how should I handle these problems?
As mentioned above, sometimes you don't need to. If the behavior of your application is acceptable even with several minutes of replication lag, then that's awesome!
If your system (or users) can't tolerate this though, you will need to enforce these guarantees for the sake of good user experience. Many vendors offer this guarantees as configurable features in their systems. The most important thing to remember is that pretending that your replication is synchronous when it's not will not help you with the problems.
Well, we reached the end of this series, and I hope you learned one or two useful things. This is a massive topic, and we just covered some fundamental concepts in one form of replication: leader/follower replication. There are other forms of replication with multiple leaders or no leaders at all. The situation gets even more interesting with the introduction of sharding: distributing the information of one database into multiple machines. This, as you imagined, is another huge topic with lots of interesting concepts and corner cases.
I hope this series helped you decide if distributed systems is a topic you want to dive deeper into. The importance of replication in modern applications can't be underestimated. You probably use several such systems daily: social media apps, productivity software and source control among others. Now when you hear about replicas, followers and replication lag you will know what they are talking about.
Thanks for reading!
What to do next:
- Share this article with friends and colleagues. Thank you for helping me reach people who might find this information useful.
- This series is based on Designing Data-Intensive Applications, make sure to take a look at chapters 5 and 6 for a more in-depth explanation of replication and sharding. This and other very helpful books can be found in the recommended reading list.
- Send me an email with questions, comments or suggestions (it's in the About Me page)
