This article is a summary of what I consider to be the most important concepts of the book Domain-Driven Design, by Eric Evans. I tried to condense the most important ideas in a single article for anyone interested in the topic. I attempted to pack in as much information as possible, but it was not an easy task: The book is a very condensed work with lots of practical examples. I urge you to read the complete book if you want to really get what this is all about. With that out of the way, let's take a look at the domain-driven design, in a single article
I think it's a good idea to start by defining what we mean by domain.
We build software because we want to solve a problem related to a specific area or activity. This activity/area is the domain of our software and can be something concrete as amigurumi dolls or as abstract as accounting.
Developers usually don't build software in isolation. Most applications require the input of domain experts who bring to the table valuable domain knowledge that developers often lack. Not every piece of knowledge about the domain is relevant, though. A team must put aside all the non-relevant details of the domain and focus on the most important concepts to build a model to serve as the base for our development.
This model will provide the team with useful abstractions needed to build software that can solve the right problems and adapt to future changes in requirements. As you might imagine, there is an infinite amount of different models for every single domain. It all depends on which details from the domain you ignore and which ones you add. The following 3 ideas will guide you in the selection of a good model:
- The model is distilled knowledge: It has only the details that are relevant to solving the problem at hand.
- The model forms the basis for the language (spoken and written) used by the team.
- The model and the implementation should shape each other through the course of the project.
Let's discuss all 3 ideas in a bit more detail.
1.Crunching knowledge
A good model helps you create objects that are more than just glorified data structures that share a name with the concept they represent. They need to have meaningful behavior and relations to other objects in the model.
You have to be selective: Add to the model important concepts and discard unimportant ones. This is hard to achieve in practice, so you will probably need to try many different iterations of the model before you find out what important means in your particular context.
At the beginning of any project, team members lack the knowledge needed to create a good model. That's fine, as the project goes on the team's knowledge base improves, and refining the model becomes easier. After several iterations business rules are better defined, ambiguities are resolved and the quality of the objects improves.
Creating a good model is hard, but engaging in continuous refinement will do the trick.
2. The model as the foundation of the team's language
Humans have amazing language skills, so we might as well use them to aid us in the design process. In most projects, the language gap between developers and domain experts can become a problem. Talking in terms of database tables or data structures might mean very little to domain experts, whereas developers might find the professional jargon of the domain confusing.
Creating a language based on the model provides the team with a tool to discuss the project with enough precision to create a technical implementation.
The team should make the effort in creating a language based on the model and using it as often as possible as an integral part of the development process.
3.Binding model and implementation
A model is much more than just a useful tool for aiding the initial stages of design. Models are the foundation of the design for the software we build.
The software entities that we create in our design should be representations of our model, but this is usually not easy. A model produced by careful analysis might be correct and still be difficult to implement.
A model that doesn't map easily into an implementation must be refined through several iterations. If done correctly we will create a model that captures the problem at hand and lends itself to and easy implementation.
Usually, the best strategy is to start with a limited design that reflects the model in a literal way with an obvious mapping. After that, we proceed to refine the model iteratively, making it easier and easier to implement without losing the essential details.
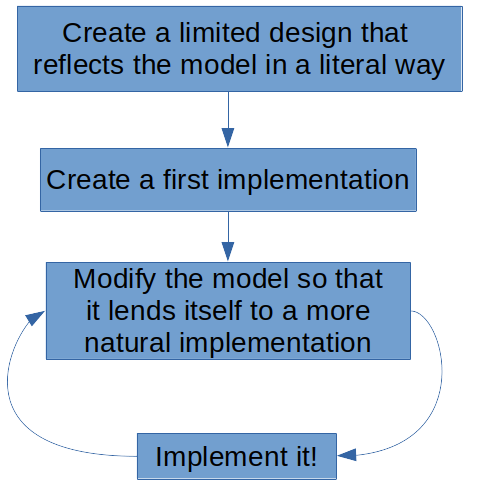
Models aren't just fancy constructs, they encode the most important knowledge about the domain. The model you produce as part of the design and development process is valuable in itself, you can make the argument that the software you make is valuable because it implements the model.
Just remember that every time you change the code (design), you perform an implicit change in the model. This is the reason all the developers in the team should be encouraged to take part in the modeling process.
Good. Now that we discussed the basic team aspects of domain-driven design, let's talk about the building blocks we can use to represent elements of a model.
Building blocks and general structure.
Layered architectures are quite useful for building software based on strong models. If you haven't heard this term before don't worry, the idea is quite simple: The software is organized into conceptual layers with well-defined responsibilities. For keeping integrity, the communication between layers is constrained: A layer can only communicate (call methods and hold references to) the layer immediately under it.
DDD can be implemented in a scheme with 4 layers:
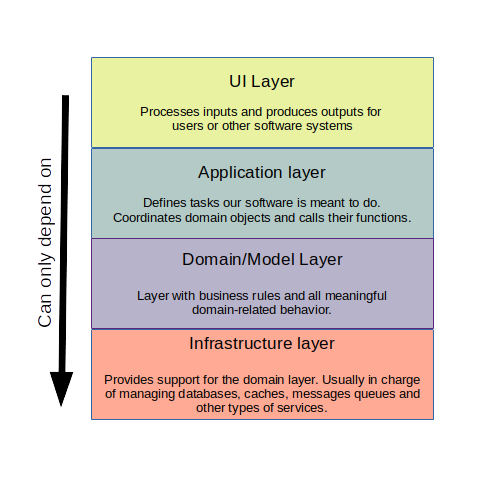
From all these layers, the one we focus on the most when doing domain-driven design is the domain layer. All the distilled knowledge will go into creating the objects that populate this layer.
Let's discuss a couple of ideas that will help you create a rich, expressive and clean domain layer.
Keep your associations simple
An association between two objects is a dependency. Holding a reference to an object, calling one of its methods, or having any knowledge about it creates a dependency on it.
Associations aren't a bad thing, in fact, without them most software would be practically impossible to build. The problem starts when the number of associations becomes unmanageably large. The secret is to keep things simple and get rid of as many unnecessary associations as possible. In practice, I've found that the biggest amount of value is gained from two things:
- Get rid of bidirectional associations (both objects depend on each other).
- Minimize the number of associations for every object in your system (duh).
It's not easy to do, but there are well-known techniques to solve this problem. Most books on design patterns or software construction will give you tools for managing object dependencies(You can check my favorites in the reading list, but almost any book on the topic is good enough).
If you don't know how to do this yet go and learn it, it will make your life much, much easier.
Understand object identity
In the book (DDD), Evans makes a distinction between objects based on their identity.
An object whose identity is defined entirely by its attributes is called a value object. Two value objects with the same attribute are essentially the same thing, and the system will treat them as such. Suppose you are building software for a car factory. Due to specific project considerations, you end up creating a type for the different Brands of car the factory makes. The Brand object is defined entirely by the attributes that make it, it's what sets a brand apart from all the rest.
If two brands were to exist at the same time the system would not be able to tell the difference. Because of this, cars don't need to have their own copies of a specificBrand, cars of the same make can all reference a single, immutable instance of their particular model in memory. Value objects tend to be either private members of other objects, one-off data containers to pass as arguments to functions, or immutable objects with multiple incoming references.
The other type of object is the entity. Entities transcend the contents of their attributes: Two entities can have the exact same attributes, but they still need to be treated as separate objects. Imagine an application that for one reason or another has an object Person with name, nationality, and favorite ice-cream flavor. Despite having the same attributes, the objects for me and my dad (Both Juan Luis Orozco, both Cost Rican, and both with mint as favorite ice cream flavor) should be treated as separate entities from creation to destruction. In practice, most objects with rich behaviors and relations in your application will be entities.
It's important to understand that the same real-world concept can take any of the two forms, this is dictated by the specifics of the problem you are trying to solve. Evans explains this with the following example:
Imagine you are building an application for managing the seats in a stadium for a ticketing system. If the application needs to take into consideration the specific seat customers book, the Seat objects will be entities: We care which seat we are going to get. If the application ignores their positions and numbers and customers can seat wherever they please, the Seat objects are going to be modeled as value objects because there is no important difference from the point of view of the ticket.
Other useful constructs
Services
Services let you model procedures in a OO way. They are objects that perform procedural tasks that don't belong to any other domain object and can find a place in any of the architectural layers we discussed before. Designing a good service is not a simple task, but most great services have some characteristics in common:
- The operations they perform relate to a domain concept that is not a natural responsibility of your entities or value objects.
- The interface is defined in terms of other elements of the domain model (both arguments and how the methods fit in the model).
- The operation they perform can have side effects, but the object that implements the service must be stateless.
Modules
Modules are a way of packaging together closely-related parts of your system. Ideally, you want to put together concepts that can be understood and reasoned independently of other parts of the model. Modules encompass a cohesive set of concepts that tell a story when put together and help you achieve high-cohesion and low coupling.
As you might suspect by now, finding the boundaries and contents of each module is not an easy task. Gaining the amount of knowledge and understanding necessary for creating a good set of module boundaries will probably take you several iterations, and that's fine.
Aggregates
Aggregates are a way of transforming a collection of objects with complicated relationships into a consistent construct that is easy to use and reason about. The following image shows a class diagram with a client object (Customer) interacting with two aggregates.
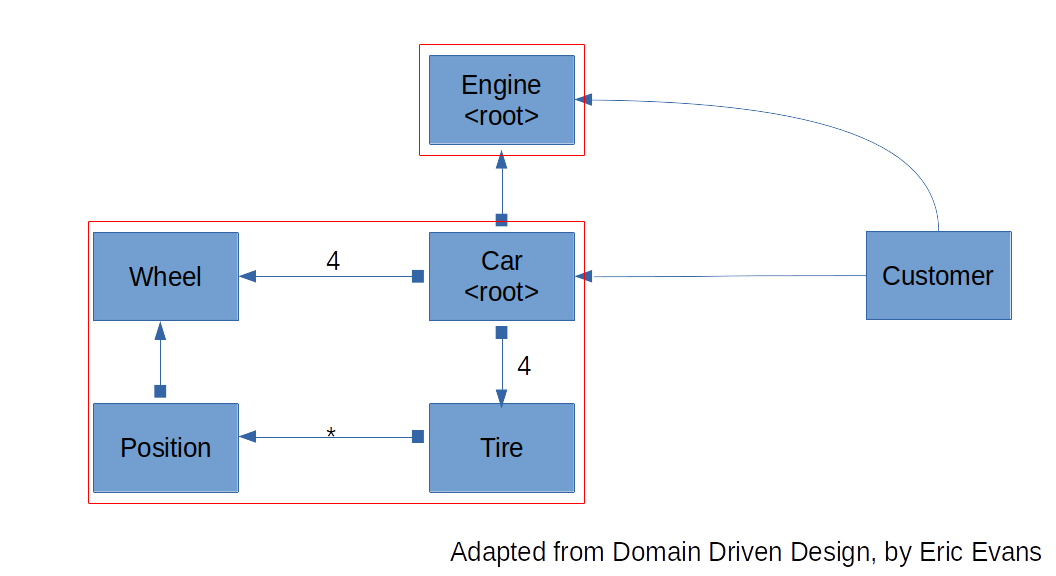
These are some important considerations when working with aggregates:
- An aggregate can contain any number of objects, but the root is always an Entity.
- Nothing outside of the aggregate boundaries can hold a reference to anything inside of it. This means that all the functionality of the aggregate is served through the root (like a Facade). In the previous example, this means that the Customer can't hold permanent references to Wheel, Position, and/or Tire.
- Roots can, in some circumstances, return a reference for an object inside of the boundary, but they can only be used by the client in a transient way.
- Objects inside of the aggregate can hold references to the roots of other aggregates.
- The root object is responsible for ensuring all the invariants of the aggregate.
- Deleting the root of an aggregate deletes all the objects in it.
Factories
Factories are useful patterns for making the creation of objects easier. In this context, they become especially useful because they can create complete aggregates and ensure they start in a valid state where all invariants are satisfied.
And yes, I am talking about the good ol' Abstract Factory and Factory Method patterns. So remember to delegate the creation of aggregates to the factories of your system.
Persistence
Almost every application needs to have some form of persistent storage for the data of the system. There are two main ways of giving your system these capabilities:
- Make use of the ActiveRecord pattern and give objects the responsibility of managing their own CRUD capabilities.
- Create a special family of objects whose only responsibility is to retrieve and store objects in a DB or any other form of storage. An object that does this is called a Repository and can be implemented in many ways depending on the project's needs.
The role of refactoring in DDD
Refactoring is usually how we call the act of performing incremental changes to the codebase to improve the structure and quality of your code. This is not what we mean by refactoring in this context.
In DDD, refactoring is about distilling the model into a better representation of the problem at hand. Changes performed to the model (and as a result, the implementation) are usually fueled by increased insight into the problems we are trying to solve. At the beginning of the project, this might be a difficult task, but after enough refactorings, we find ourselves at a point where modest time investments provide huge value increases in functionality.
Pay attention to the insights you gain as the project advances, and don't ignore an opportunity to improve a model. Really, don't be afraid to 'break it', models are malleable, and the potential benefits are huge!
Models are usually improved by taking an implicit concept and making it explicit. And yes, unfortunately, there is no shortcut to achieving this.
You will need to use the project's model language, talk to experts in the field, read books and refactor until you find the most important concepts. It's hard work, but all these things will help you in creating consistent, flexible, and explicit models that will make implementing new features fast and easy.
Supple design
According to Evans, a supple design is A design that puts the power inherent in a deep model into the hands of a client developer to make clear, flexible expressions that give expected results robustly. Equally important, it leverages that same deep model to make the design itself easy for the implementer to mold and reshape to accommodate new insight.
Sounds nice, doesn't it? The goal of the book (and this article) is to give you tools for achieving a supple design in any project you tackle. We have already discussed most of the domain-driven design fundamentals you will use to achieve this goal. These are other helpful ideas that will aid you in this task:
- Create intention-revealing interfaces. The names of the functions and their parameters must speak an intent.
- Use assertions for preventing unexpected behavior and also for expressing intent.
- Decompose design elements (interfaces, classes, aggregates) into cohesive units with clearly defined boundaries.
- When possible, use a declarative style of architecture that can express functionality as behavior combinations.
- Refresh your knowledge of design patterns and analysis patterns. If you don't know where to start grab a copy of Analysis patterns by Martin Fowler.
Maintaining model integrity
If a system is large enough, smaller models will start to sprout in different parts of the system. This is one of the reasons keeping model integrity becomes harder as systems grow. Let's take a look at some of the things you can do to protect your model from corruption if you find yourself working on a big enough project:
Bounded context
When code from different modules is combined, bugs eventually arise. You need to identify the context (parts of the system) where the model applies and protect it at all costs from creeping inconsistencies. Your team should watch out for inconsistencies inside of those boundaries at all times and correct them immediately.
Context map
When multiple models in the system emerge, you need to find a way to figure how concepts in the two models relate. For this, create a context map that explicitly specifies these relationships.
Shared kernel
Sometimes, two or more models will have a part in common that you can't separate. For this, designate the shared pieces as the shared kernel of your models. Teams can't make changes to the shared kernel without consulting each other to keep consistency.
Anticorruption layer
An anticorruption layer provides clients with functionality in terms of their own models. This way, you can keep the two parts of the system isolated and consistent. If you need to access functionality from the other parts of the system you can use the interfaces they already have in place.
Distillation
These are some ideas you can use to split your model into different sub-sections:
Core model: The core model is the most important part of the system, the essence of the problem your software solves, separate it from the supporting models.
Separate generic concepts: Grab the parts of your system that represent generic problem features and put them into their own model.
Separate mechanisms: Grab the procedural/mechanical parts of your system and hide them behind an interface. If you need to provide your objects with some graph-like behavior, code it into its own construct and provide the feature through a clean interface.
Final considerations
These are some other ideas for enriching the domain-driven design process:
- The design process must absorb feedback. Continuous communication and collaboration from every team member are essential for coming up with a successful model.
- Decisions must reach the entire team. DDD is not an 'ivory tower architect* process and requires that team members contribute and have a say in design matters.
- Make a place in your design for the dynamic nature of the process. It will change, several times, before you reach a satisfactory solution.
- Good design requires both minimalism and humility.
Thanks for reading
I am a believer in the importance of investing in our own professional growth as software developers and technology professionals. Lots of important ideas and processes have been documented in the last decades, but somehow we find ourselves learning the same lessons over and over again.
Lots of great books and documents have been written on the topic of making great software, and Domain-Driven Design is, in my opinion, one of the most important ones. I spend a lot of time trying to write an article with all the important stuff, but it's almost impossible to do it justices with so little space.
I really recommend the book. Despite being almost two decades old, I find the contents to be both refreshing and enlightening for the modern development world. Perhaps because of the importance that software has nowadays, I'd dare to say that it's never been as relevant as it is today.
So, if you have the time go and take a look, it's really worth it.
Thanks for reading!
What to do next
- Share this article with friends and colleagues. Thank you for helping me reach people who might find this information useful.
- This article is based on Domain-Driven Design, by Eric Evans. These and other very helpful books can be found in the recommended reading list.
- Send me an email with questions, comments or suggestions (it's in the About Me page)
