En el artículo anterior de la serie, respondimos nuestra primera pregunta: ¿qué es la ciencia de datos y qué contribuciones llevaron a su creación?
En este artículo exploraremos otra pregunta importante:
¿Cuándo debería usar ciencia de datos?
La ciencia de datos tiene montones de aplicaciones increíblemente útiles en campos tan diversos como las finanzas, la planificación forestal y la investigación genética. Aprender sobre los casos de uso más comunes para proyectos de ciencia de datos te ayudará a decidir si es una buena opción para los problemas que estás enfrentando.
Pero antes de eso, aprendamos sobre los requisitos básicos para un proyecto de ciencia de datos.
¿Qué necesito cuando necesito ciencia de datos?
Para que un proyecto de ciencia de datos sea exitoso, necesitarás:
Una definición clara del problema:
Debes saber de antemano qué problema estás tratando de resolver. Esto significa que necesitas tener metas y requisitos claramente definidos antes de empezar a buscar una solución. Esto parece obvio, pero no es raro ver gerentes entusiastas instando a las organizaciones a adoptar ciencia de datos como parte de su trabajo diario. Esto es tierno y se aprecia el esfuerzo, pero usar ciencia de datos solo porque sí únicamente puede resultar en proyectos fallidos y recursos desperdiciados.
Suficientes datos de buena calidad:
No es cierto que necesites petabytes de datos para cada proyecto de ciencia de datos. Hay montones de proyectos que requieren conjuntos de datos mucho, mucho más pequeños. Lo que necesitas son suficientes datos de buena calidad. Quiero enfatizar la palabra calidad, lo que significa que tienes datos completas, actualizadas y relevantes.
La relevancia es uno de los aspectos más importantes: imagina que quieres crear un modelo de predicción para la propensión de un individuo a desarrollar cáncer. En este caso, te gustaría conocer el peso de la persona, edad, cantidad de actividad física semanal, hábitos de fumar y beber, entre otros. Puedes descartar cosas como el tamaño del zapato, película favorita, la primera letra de su apellido y otros detalles que no parecen contribuir al desarrollo de una enfermedad.
Una pregunta que un experto humano no puede responder solo
La ciencia de datos es especialmente útil cuando se abordan problemas que no pueden reducirse a una serie de pasos o ser respondidos por un experto humano. Si puedes especificar una serie de pasos de bajo nivel que resuelvan un problema, entonces la programación tradicional puede manejarlo.
Si un experto humano puede examinar los datos y encontrar todos los patrones solo, entonces no necesitas usar todo el poder de la ciencia de datos para obtener perspectivas/insights de él, a menos que necesites que la tarea se realice automáticamente y a menudo.
Problemas como crear un sistema que detecte si una imagen tiene una guitarra, hacer que este auto se conduzca solo o predecir los precios de las casas en Budapest para los siguientes seis meses son todos buenos candidatos para ciencia de datos. Problemas como encuéntrame si esta palabra en español tiene un diptongo o ¿alcanzamos nuestros objetivos de ingresos trimestrales? … no tanto.
Experiencia y autoridad para tomar acción
Este parece obvio, pero sí, necesitas tener profesionales relevantes en el campo para poder usar ciencia de datos. Esto incluye tanto profesionales de ciencia de datos que puedan procesar los datos y proporcionarte modelos e perspectivas/insights como profesionales del dominio que puedan tomar acción basándose en los hallazgos.
Obtener un reporte completo lleno de perspectivas/insights valiosos y ponerlo en el cajón no tiene sentido. Lo mismo pasa con tener un modelo predictivo en línea e ignorarlo todo el tiempo.
Ahora que entendemos algunos de los requisitos básicos, echemos un vistazo al tipo de problemas que la ciencia de datos intenta resolver.
Enmarcando tu problema en términos de ciencia de datos
Hay diferentes tipos de sub-problemas en ciencia de datos, cada uno con algoritmos y técnicas específicas usadas para encontrar las mejores soluciones. Entender qué tipo de problema estás abordando te permitirá seleccionar las mejores herramientas para el trabajo. Aprendamos sobre los 5 tipos de problema más comunes.
Regresión
En un problema de regresión quieres crear un modelo que prediga un valor continuo. Esta es una sub-categoría de los problemas conocidos como problemas de predicción.
El flujo de trabajo usual generalmente involucra la recolección de datos relevantes al tema, que formarán parte del conjunto de entrenamiento. Estos datos serán pasados a diferentes algoritmos que crean modelos predictivos. El rendimiento de estos modelos predictivos es evaluado y el mejor es elegido e implementado.
Algunos ejemplos de problemas predictivos son:
-
Crear un modelo que prediga los precios de casas en diferentes partes de Bélgica basándose en el ingreso promedio de la ciudad, la ubicación y la proximidad a una panadería.
-
Crear un modelo que prediga tu probabilidad de desarrollar cáncer en los siguientes 10 años basándose en tu edad, IMC, el número de cigarrillos que fumas por día y por cuánto tiempo has estado fumando.
-
Crear un modelo que te diga la probabilidad de que un Pokemon le gane a otro.

Clasificación
Este es otro tipo de problema de predicción. La diferencia entre clasificación y regresión es que mientras el último devuelve un valor continuo como resultado de la predicción, un modelo de clasificación te dice a qué categoría pertenece la entrada.
Y al igual que en el caso de regresión necesitas ejemplos etiquetados para entrenar el modelo. Esto usualmente viene en forma de datos históricos con atributos relevantes.
-
El ‘hola mundo’ de los problemas de clasificación es averiguar si un email es spam o no-spam basándose en sus contenidos.
- Identificar el género musical de una canción basándose en sus letras y título.
- Categorizar clientes con alta probabilidad de dejar la empresa como clientes de alerta de abandono y notificar a agentes especializados para tomar acción y recuperar su buena voluntad.
- Decirte si un pokemon apesta o es genial.
Aprendizaje de reglas de asociación
El aprendizaje/minería de reglas de asociación es un método para descubrir relaciones entre elementos en grandes conjuntos de datos. Un ejemplo típico es usarlo para identificar qué productos tienen más probabilidad de ser comprados juntos.
La minería de reglas de asociación usualmente se usa para apoyar la venta cruzada. Esto es cuando las empresas ofrecen al cliente productos extra que podrían haber olvidado o de los que aún no saben. Como ejemplo, si estás comprando una guitarra nueva y un amplificador, también podrías querer comprar un cable o cuerdas nuevas.
Esto se hace mediante algoritmos que escanean información transaccional histórica y buscan la co-ocurrencia de elementos. Generarán una serie de reglas que modelan la probabilidad de que ciertos elementos sean comprados juntos. Dos de los valores más importantes generados por estos algoritmos son soporte y confianza.
- Soporte/Apoyo (Support, no encontré una mejor traducción) es la proporción de transacciones que incluyen el conjunto específico de elementos contra el número total de transacciones. Te dice qué tan frecuentemente ocurren juntos el conjunto de elementos. Por ejemplo, si {guitarra, amplificador, cable} tienen un valor de soporte del 2%, significa que el 2% de todas las compras incluyen los 3 elementos.
- Confianza es una medida de qué tan probable es que Z sea comprado si ya estamos comprando A. Se define como la proporción entre las transacciones que incluyen Z y A contra todas las que incluyeron A. Una confianza del 30% entre guitarra y amplificador significa que el 30% de los clientes que compraron una guitarra también compraron un amplificador.
Estos algoritmos pueden generar cantidades masivas de reglas y no todas son útiles. A menudo, solo se permite que permanezcan las reglas con valores altos de soporte y confianza, el resto se descarta.
Las tiendas físicas pueden usar esta información para agrupar elementos juntos para promover compras, y las tiendas en línea pueden ofrecerte elementos al momento del pago e incluso proporcionar algunos descuentos para elementos específicos. Es conocido que la información demográfica sobre clientes aumenta la efectividad de estos algoritmos, por eso la mayoría de las tiendas ofrecen tarjetas de lealtad con descuentos a cambio de tus datos.
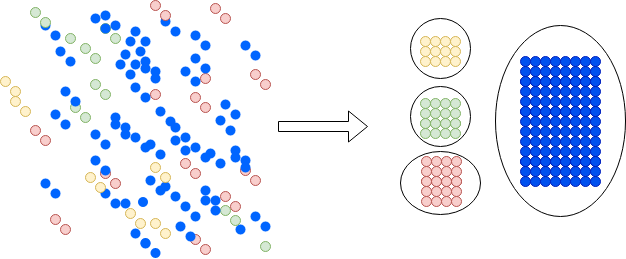
Segmentación
La segmentación es una de las técnicas de ciencia de datos más útiles. Su objetivo es agrupar los elementos de un conjunto de datos en subgrupos que tengan características en común. Mientras que la tarea no es tan difícil en un plano 2D, conjuntos con muchos atributos hacen imposible que un humano logre esta tarea. Al aprovechar la ciencia de datos puedes encontrar algunos grupos útiles y contraintuitivos en los datos.
La segmentación puede mejorar dramáticamente la efectividad de las campañas de marketing. En lugar de enviar la misma campaña a todos, podrías crear segmentos de usuarios y dirigirte a ellos solo con la información que necesitan. Incluso puedes crear campañas especializadas dirigidas a diferentes subgrupos. Esto tiene dos ventajas: primero, no molestas a la gente con ofertas que no les importan. Segundo, te permite ahorrar dinero y aumentar el éxito de las campañas enfocando los recursos donde tienes más posibilidades de tener éxito.
Las máquinas son mucho mejores descubriendo subconjuntos desconocidos en los datos que los humanos. Después de que han creado segmentos, un experto humano puede inspeccionar el conjunto para asegurar que tengan sentido.
Esta técnica trasciende más allá del marketing y tiene una amplia gama de aplicaciones, que van desde identificar secuencias de genes hasta patrones en grupos poblacionales, ecosistemas y documentos.
Detección de valores atípicos
La detección de valores atípicos es en cierto modo lo opuesto a la segmentación. En segmentación, quieres crear grupos que contengan solo elementos similares, en detección de valores atípicos quieres separar las instancias que son diferentes del resto. El objetivo de la detección de valores atípicos es encontrar anomalías o casos especiales dentro de nuestro conjunto de datos.
Esto se puede lograr de 3 maneras:
- Crear dos grandes grupos de datos usando segmentación. Los casos típicos serán agrupados juntos y los valores atípicos serán los elementos fuera del grupo.
- Medir la distancia entre cada elemento y el centro de los datos. Las anomalías usualmente serán las que estén más lejos del grupo.
- Entrenar un modelo de clasificación para dividir instancias en dos grupos. Esto es difícil porque necesitas (como recordarás) datos de entrenamiento para el clasificador, y los valores atípicos son por definición raros, representando solo una pequeña porción del conjunto de entrenamiento. Esto afecta el rendimiento de muchos tipos de clasificadores.
La detección de valores atípicos es usada por instituciones financieras para identificar transacciones fraudulentas u otras formas de comportamiento fraudulento. También puede usarse para detectar actividad de red maliciosa o ataques en sistemas de software.

Date la oportunidad de aprender algo sobre ciencia de datos
Esta es solo una pequeña introducción a todas las posibles aplicaciones que tiene la ciencia de datos. La lista de ejemplos en diferentes campos que se benefician del análisis automático de datos es masiva, y sigue creciendo.
Ahora que sabes para qué se usa la ciencia de datos es hora de explorar otra pregunta: ¿por qué?
En el próximo artículo, hablaremos sobre las motivaciones y beneficios detrás del uso generalizado de la ciencia de datos.
Qué hacer después
- Comparte este artículo con amigos y colegas. Gracias por ayudarme a llegar a personas que podrían encontrar útil esta información.
- Esta serie está basada en los libros de la serie MIT Essential Knowledge sobre ciencia de datos y machine learning.
- Envíame un email con preguntas, comentarios o sugerencias (está en la página Autor)