In the previous article of the series, we answered our first question: what is data science and which contributions led to its creation?
In this article we will explore another important question:
When should I use data science?
DS has lots of incredibly useful applications in fields as diverse as finance, forest planning, and genetics research. Learning about the most common use cases for data science projects will help you decide if it’s a good fit for the problems you are facing.
But before that, let’s learn about the basic requirements for a data science project.
What do I need when I need data science?
For a data science project to be successful, you will need:
A clear problem definition:
You must know beforehand which problem you are trying to solve. This means that you need to have clearly defined goals and requirements before you start looking for a solution. This seems obvious, but it’s not uncommon to see enthusiastic managers urging organizations to adopt data science as part of their daily work. This is sweet and the effort is appreciated, but using data science just because can only result in failed projects and wasted resources.
Enough good quality data:
It’s not true that you need petabytes of data for every data science project. There are lots of projects that require way, way smaller datasets. What you need is enough good quality data. I want to emphasize the word quality, meaning that you have complete, up-to-date and relevant pieces of data.
Relevance is one of the most important aspects: imagine you want to create a prediction model for the propensity of an individual to develop cancer. In this case, you would like to know the person’s weight, age, amount of weekly physical activity, smoking and drinking habits, among others. You can ditch things like shoe size, favorite film, the first letter of his/her last name and other details that don’t seem to contribute to developing a disease.
A question a human expert can’t answer alone
Data science is especially useful when tackling problems that can’t be reduced to a series of steps or answered by a human expert. If you can specify a series of low-level steps that solve a problem then traditional programming can handle it.
If a human expert can examine the data and find all the patterns alone, then you don’t need to use the full power of data science to gain insights from it, unless you need the task to be performed automatically and often.
Problems like create a system that detects if an image has a guitar, make this car drive itself or predict the prices of houses in Budapest for the following six months are all good fits for data science. Problems like find me if this word in Spanish has a diphthong or did we hit our quarterly revenue targets … not that much.
Expertise and the authority to take action
This one seems obvious, but yes, you need to have relevant professionals in the field to be able to use data science. This includes both data science professionals that can crunch the data and provide you models and insights and domain professionals who can take action based on the findings.
Getting a complete report full of valuable insights and putting it in the drawer is pointless. So is having an online predicting model and ignoring it all the time.
Now that we understand some of the basic requirements, let’s take a look at the type of problems data science attempts to solve.
Framing your problem in data science terms
There are different types of sub-problems in data science, each with specific algorithms and techniques used to find the best solutions. Understanding what type of problem you are tackling will let you select the best tools for the job. Let’s learn about the 5 most common types of problem.
Regression
In a regression problem you want to create a model that predicts a continuous value. This is a sub-category of the problems known as predictions problems.
The usual workflow usually involves the collection of data relevant to the topic, which will form part of the training set. This data will be fed into different algorithms that create predictive models. The performance of these predictive models is evaluated and the best one is chosen and deployed.
Some examples of predictive problems are:
-
Creating a model that predicts the house prices in different parts of Belgium based on the average income of the city, the location and the proximity to a bakery.
-
Creating a model that predicts your likelihood to develop cancer in the following 10 years based on your age, BMI, the number of cigarettes you smoke per day and how long you’ve been smoking.
-
Creating a model that tells you the likelihood of a Pokemon beating another one.

Classification
This is another type of prediction problem. The difference between classification and regression is that while the former returns a continuous value as the result of the prediction, a classification model tells you what category the input belongs to.
And just like in the case of regression you need labeled examples to train the model. This usually comes in the form of historic data with relevant attributes.
-
The ‘hello world’ of classification problems is finding out if an email is spam or not-spam based on its contents.
- Identify the musical genre of a song based on its lyrics and title.
- Categorize clients with a high likelihood of leaving the company as churn alert customers and notify specialized agents to take action and regain their goodwill.
- Tell you if a pokemon sucks or is awesome.
Association rule learning
Association rule learning/mining is a method for discovering relations between elements in large datasets. A typical example is using it to identify which products are more likely to be purchased together.
Association rule mining is usually used to support cross-selling. This is when companies offer the customer extra products they might have forgotten or don’t know about yet. As an example, if you are buying a new guitar and an amplifier, you might also want to buy a cable or new strings.
This is done by algorithms that scan historic transactional information and look for the co-occurrence of items. It will generate a series of rules that model the likelihood of certain items being bought together. Two of the most important values generated by these algorithms are support and confidence.
- Support is the ratio of transactions that include the specific set of items against the total number of transactions. It tells you how frequently the set of items occur together. For example, if {guitar, amplifier, cable} have a support value of 2%, it means that 2% of all purchases include all 3 items.
- Confidence is a measure of how likely it is that Z will be bought if we are already buying A. It is defined as the ratio between the transactions that include Z and A against all the ones that included A. A confidence of 30% between guitar and amplifier means that 30% of the customers who bought a guitar also bought an amplifier.
These algorithms can generate massive amounts of rules and not all of them are useful. Often, only rules with high values of support and confidence are allowed to stay, the rest are discarded.
Physical stores can use this information to group items together to promote purchases, and online stores can offer you items at checkout-time and even provide some discounts for specific items. It is known that demographic information about customers increases the effectiveness of these algorithms, so most shops offer loyalty cards with discounts in exchange for your data.
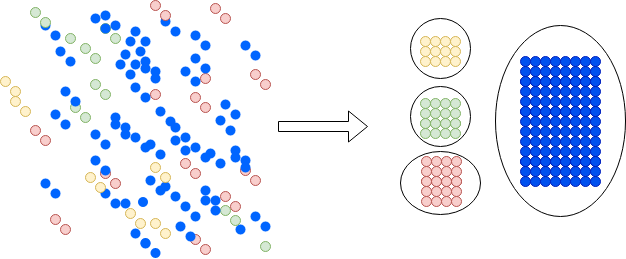
Segmentation
Segmentation is one of the most useful data science techniques. It aims to group the elements of a dataset into subgroups that have characteristics in common. While the task is not that difficult in a 2d plane, sets with lots of attributes make it impossible for a human to accomplish this task. By leveraging data science you can find some useful and counterintuitive groups in data.
Segmentation can dramatically improve the effectiveness of marketing campaigns. Instead of sending the same campaign to everyone, you could create segments of users and target them with only the information they need. You can even create specialized campaigns aimed at different subgroups. This has two upsides: first, you don’t bother people with offerings they don’t care about. Second, it lets you save money and increase the success of campaigns by focusing the resources were you have the most chances to succeed.
Machines are much better at uncovering unknown subsets in data than humans are. After they have created segments, a human expert can inspect the set to ensure they make sense.
This technique transcends beyond marketing and has a wide array of application, ranging from identifying gene sequences to patterns in population groups, ecosystems and documents.
Outlier detection
Outlier detection is in some way the opposite of segmentation. In segmentation, you want to create groups containing only similar elements, in outlier detection you want to separate the instances that are different from the rest. The goal of outlier detection is to find anomalies or special cases within our dataset.
This can be achieved in 3 ways:
- Create two big clusters of data using segmentation. Typical cases will be grouped together and outliers will be the elements out of the group.
- Measure the distance between each element and the center of the data. Anomalies will usually be the ones farther away from the group.
- Train a classification model to divide instances into two groups. This is difficult because you need (as you remember) training data for the classifier, and outliers are by definition rare, representing just a small portion of the training set. This affects the performance of many types of classifiers.
Outlier detection is used by financial institutions to identify fraudulent transactions or other forms of fraudulent behavior. It can also be used to detect malicious network activity or attacks on software systems.

Dip your toes in data science
This is just a small introduction to all the possible applications data science has. The list of examples in different fields that benefit from automatic data analysis is massive, and it just keeps growing.
Now that you know what data science is used for it’s time to explore another question: why?
In the next article, we will talk about the motivations and benefits behind the widespread use of data science.
What to do next
- Share this article with friends and colleagues. Thank you for helping me reach people who might find this information useful.
- This series is based on the MIT Essential Knowledge series books on data science and machine learning.
- Send me an email with questions, comments or suggestions (it’s in the About Me page)