We have already covered most of the fundamentals of working with data using the Pandas library. There is one more topic I'd like to discuss before concluding the series: The Apply function.
In the previous article, we learned how to create subgroups of data using the groupby function. This is quite useful when you want to gain a better understanding of certain subsets of data or perform group aggregations. Today we will add another resource to your toolbox that will let you use those groups for much more.
Apply lets you perform more complex computations on the groups you create, it works like this: The function you provide to apply is called on each of the groups, and the results are concatenated into a single final data structure.
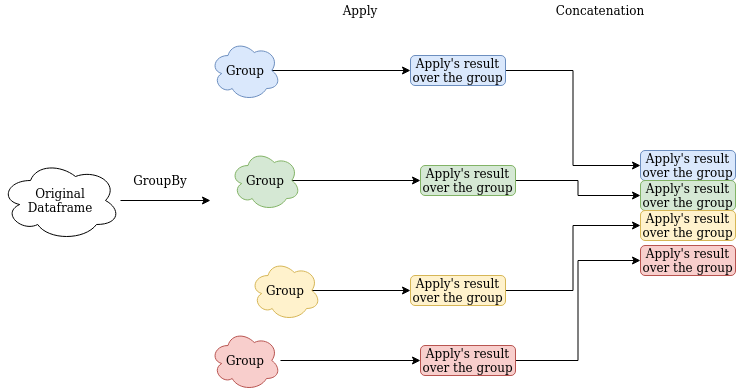
Again, this is much easier to understand with practical examples, so let's get started!
Basic applications of apply
We will use the same table with Pokemon data we used in the last article.
First, let's import pandas and examine the contents of our DataFrame.
import pandas as pd
pdata = pd.read_csv('./sample_data/poke_colors.csv')
pdata
| Name | Color | Evolves | HP | Attack | Defense | SpAtk | SpDef | Speed | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | Caterpie | Green | True | 45 | 30 | 35 | 20 | 20 | 45 |
| 1 | Metapod | Green | True | 50 | 20 | 55 | 25 | 25 | 30 |
| 2 | Scyther | Green | False | 70 | 110 | 80 | 55 | 80 | 105 |
| 3 | Bulbasaur | Green | True | 45 | 49 | 49 | 65 | 65 | 45 |
| 4 | Dratini | Blue | True | 41 | 64 | 45 | 50 | 50 | 50 |
| 5 | Squirtle | Blue | True | 44 | 48 | 65 | 50 | 64 | 43 |
| 6 | Poliwag | Blue | True | 40 | 50 | 40 | 40 | 40 | 90 |
| 7 | Poliwhirl | Blue | True | 65 | 65 | 65 | 50 | 50 | 90 |
| 8 | Charmander | Red | True | 39 | 52 | 43 | 60 | 50 | 65 |
| 9 | Magmar | Red | False | 65 | 95 | 57 | 100 | 85 | 93 |
| 10 | Paras | Red | True | 35 | 70 | 55 | 45 | 55 | 25 |
| 11 | Parasect | Red | False | 60 | 95 | 80 | 60 | 80 | 30 |
| 12 | Pikachu | Yellow | True | 35 | 55 | 40 | 50 | 50 | 90 |
| 13 | Abra | Yellow | True | 25 | 20 | 15 | 105 | 55 | 90 |
| 14 | Psyduck | Yellow | True | 50 | 52 | 48 | 65 | 50 | 55 |
| 15 | Kadabra | Yellow | True | 40 | 35 | 30 | 120 | 70 | 10 |
Apply's most important argument is a function. This function will be run on every group of data and the results will be concatenated in a final data structure. We will create a simple function that returns the two Pokemon with the highest attack value, something like this:
# Two pokes with the highest attack
def highest_attack(data_frame):
# Remember how [] works, this selects the last two (highest) Attack entries after sorting
return data_frame.sort_values(by='Attack')[-2:]
# Let's test it on the complete dataframe
highest_attack(pdata)
| Name | Color | Evolves | HP | Attack | Defense | SpAtk | SpDef | Speed | |
|---|---|---|---|---|---|---|---|---|---|
| 11 | Parasect | Red | False | 60 | 95 | 80 | 60 | 80 | 30 |
| 2 | Scyther | Green | False | 70 | 110 | 80 | 55 | 80 | 105 |
Now let's see how to use apply to do something a bit more interesting. We want to find the two pokemon with the highest attack value on a by-color basis. For doing this, we will group them by Color and then pass highest_attack to apply, something like this:
# Now, let's find which are the two pokemon with the highest attack on each color group:
pdata.groupby('Color').apply(highest_attack)
| Name | Color | Evolves | HP | Attack | Defense | SpAtk | SpDef | Speed | ||
|---|---|---|---|---|---|---|---|---|---|---|
| Color | ||||||||||
| Blue | 4 | Dratini | Blue | True | 41 | 64 | 45 | 50 | 50 | 50 |
| 7 | Poliwhirl | Blue | True | 65 | 65 | 65 | 50 | 50 | 90 | |
| Green | 3 | Bulbasaur | Green | True | 45 | 49 | 49 | 65 | 65 | 45 |
| 2 | Scyther | Green | False | 70 | 110 | 80 | 55 | 80 | 105 | |
| Red | 9 | Magmar | Red | False | 65 | 95 | 57 | 100 | 85 | 93 |
| 11 | Parasect | Red | False | 60 | 95 | 80 | 60 | 80 | 30 | |
| Yellow | 14 | Psyduck | Yellow | True | 50 | 52 | 48 | 65 | 50 | 55 |
| 12 | Pikachu | Yellow | True | 35 | 55 | 40 | 50 | 50 | 90 |
Notice how the final table is the result of concatenating together the results of running highest_attack on every group!
Functions with extra arguments
The functions you pass to the apply method can receive additional arguments. Let's create another version of our function, this time called highest_attribute, that lets you specify the attribute to take into consideration and the n highest pokemon you want to select from each group:
# We set the default attribute as HP and the default n to 2
def highest_attribute(data_frame, attribute='HP', n=2):
return data_frame.sort_values(by=attribute)[-n:]
pdata.groupby('Color').apply(highest_attribute, 'Defense', 3)
| Name | Color | Evolves | HP | Attack | Defense | SpAtk | SpDef | Speed | ||
|---|---|---|---|---|---|---|---|---|---|---|
| Color | ||||||||||
| Blue | 4 | Dratini | Blue | True | 41 | 64 | 45 | 50 | 50 | 50 |
| 5 | Squirtle | Blue | True | 44 | 48 | 65 | 50 | 64 | 43 | |
| 7 | Poliwhirl | Blue | True | 65 | 65 | 65 | 50 | 50 | 90 | |
| Green | 3 | Bulbasaur | Green | True | 45 | 49 | 49 | 65 | 65 | 45 |
| 1 | Metapod | Green | True | 50 | 20 | 55 | 25 | 25 | 30 | |
| 2 | Scyther | Green | False | 70 | 110 | 80 | 55 | 80 | 105 | |
| Red | 10 | Paras | Red | True | 35 | 70 | 55 | 45 | 55 | 25 |
| 9 | Magmar | Red | False | 65 | 95 | 57 | 100 | 85 | 93 | |
| 11 | Parasect | Red | False | 60 | 95 | 80 | 60 | 80 | 30 | |
| Yellow | 15 | Kadabra | Yellow | True | 40 | 35 | 30 | 120 | 70 | 10 |
| 12 | Pikachu | Yellow | True | 35 | 55 | 40 | 50 | 50 | 90 | |
| 14 | Psyduck | Yellow | True | 50 | 52 | 48 | 65 | 50 | 55 |
Notice how the additional parameters are passed to the apply function, not to sort_values itself. Internally, apply makes sure that the right parameters are passed to whatever function it's applying.
Using lambdas as an argument for apply
As a final note, sometimes you won't want to write a complete function definition if what you want to accomplish is very simple. In this case, you can pass a lambda function. In our next example we will use this approach to select from each group the pokemon whose name appears first in alphabetical ordering in each group:
pdata.groupby('Color').apply(lambda df: df.sort_values('Name').head(1) )
| Name | Color | Evolves | HP | Attack | Defense | SpAtk | SpDef | Speed | ||
|---|---|---|---|---|---|---|---|---|---|---|
| Color | ||||||||||
| Blue | 4 | Dratini | Blue | True | 41 | 64 | 45 | 50 | 50 | 50 |
| Green | 3 | Bulbasaur | Green | True | 45 | 49 | 49 | 65 | 65 | 45 |
| Red | 8 | Charmander | Red | True | 39 | 52 | 43 | 60 | 50 | 65 |
| Yellow | 13 | Abra | Yellow | True | 25 | 20 | 15 | 105 | 55 | 90 |
Practice makes perfect
Apply is an incredibly flexible function that, if used in creative ways, lets you solve a huge variety of problems in data manipulation and transformation. This article exposed you to the basic concepts of the function, but make sure to study it further and experiment with real datasets.
As a closing remark, I'd like to share a quotation from the book Python For Data Analysis (2nd), in which this series is largely based on:
Beyond these basic usage mechanics, getting the most out of apply
may require some creativity. What occurs inside the function
passed is up to you; it only needs to return a pandas object or a
scalar value. The rest of this chapter will mainly consist of examples
showing you how to solve various problems using groupby
That's all the Pandas I can share, for now
With this article, we conclude our Hands-on Pandas series. It's been a lot of fun to write, and I really hope you learned one or two interesting things along the way.
Pandas, like every other software tool or skill, requires a good amount of practice before it becomes truly useful. Don't worry if you don't immediately know how to tackle a dataset or which function to call, with experience and continued exposure it will become second nature.
If you need help, remember that Pandas has some of the best docs around and a huge, helpful community that will guide you into finding a solution. I wish you a happy and productive learning process!
Thank you for reading!
What to do next
- Share this article with friends and colleagues. Thank you for helping me reach people who might find this information useful.
- You can find the source code for this series in this repo.
- This article is based on Python for Data Analysis. These and other very helpful books can be found in the recommended reading list.
- Send me an email with questions, comments, or suggestions (it's in the About Me page)
