In the previous article we learned the basics of replication and why is it useful to learn about it.
We also learned about leader/follower replication. We select a replica to be the leader and clients will only be able to send writes to this replica. After a write is processed by the leader it notifies every follower (the other replicas in the system) about the changes, and they perform updates to their own data.
Replicas will fail sooner or later, and there is little you can do to prevent it. Knowing how replication systems handle the addition of new nodes and how data is recovered is important for understanding what's going on in your system. Let's explore some of the most important ideas behind failure recovery in replication systems.
Adding new followers to the party
The first important topic about recovery is the addition of new replicas. You might want to add new nodes to your system for two main reasons:
- The systems need to support a higher number of reads and you want to add new replicas to keep up with the demand.
- Other replicas in your system crashed and you need to start new ones to keep up with the load.
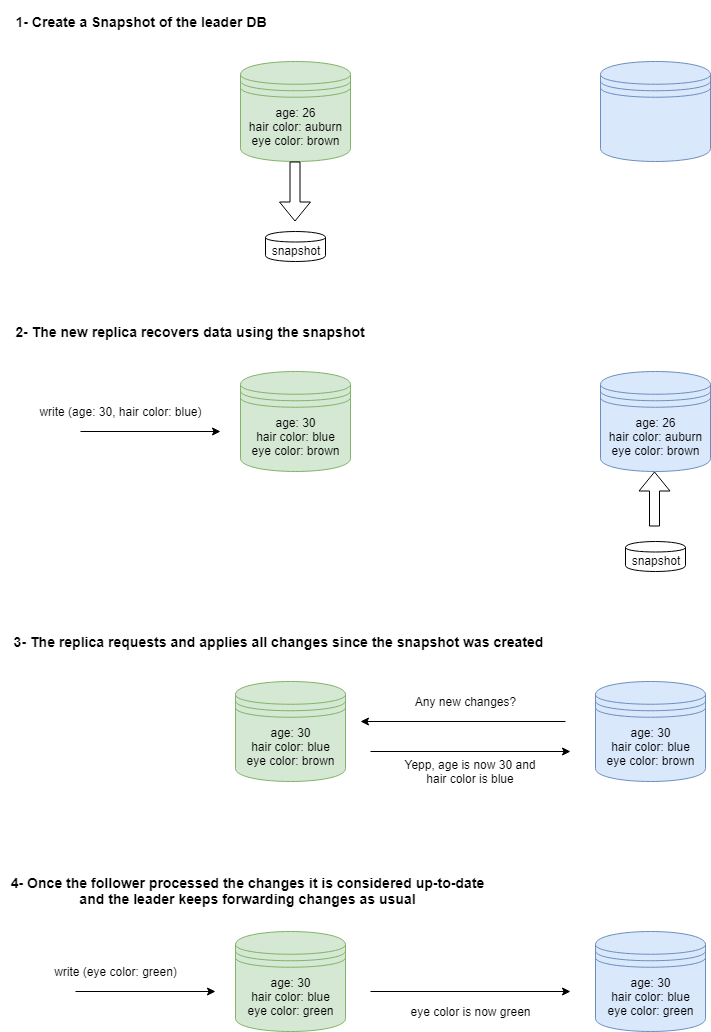
Copying the data directly into the new node usually is not enough, as new writes and updates will keep coming. By the time your node thinks it caught up, it will be out of date. The step-by-step setup for a new node usually is as follows:
- The system takes a snapshot of the data in the leader at a given point in time T.
- The snapshot is moved into the new replica and used to recover data up to the point T.
- Connect the follower to the leader and request all changes that happened since T.
- Once the follower is done processing all the changes log, it's considered up-to-date and can continue processing logs as normal.
Recovering nodes that were already running
Our system should be able to continue running even if individual nodes fail. There are multiple reasons our nodes might go offline, like crashes or network issues. We might even restart them on purpose to install security updates or other software. The way nodes recover depend on their type, leaders and followers recover using different means.
Recovering followers
The recovery process for followers is very straightforward:
- Every follower keeps a local log of the changes performed on their local copies of the data.
- Once the follower is back online, it reads the log and sees how far behind the leader it currently is.
- The follower requests all changes it's missing from the leader and processes the changes.
- After every change has been applied to local data, it considers itself up-to-date and continues to work receiving the usual change stream from the leader.
Recovering leaders
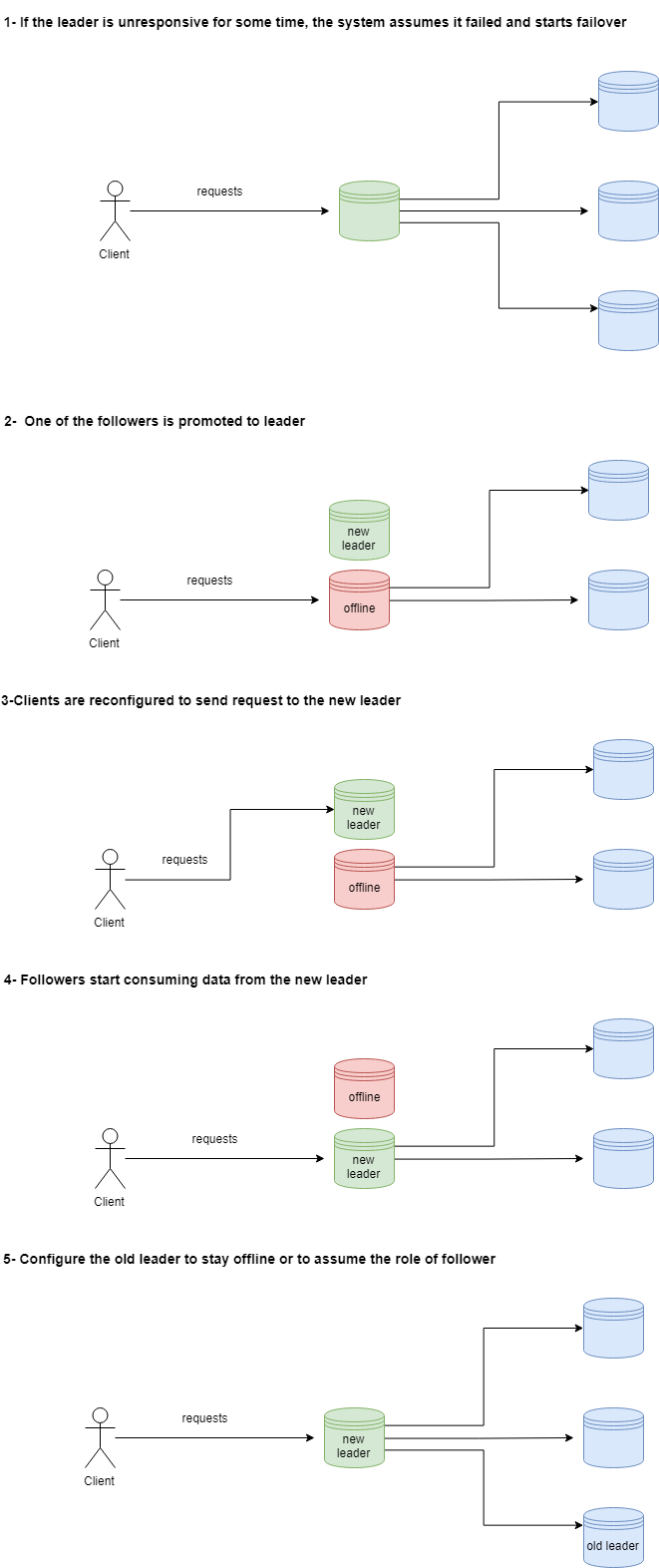
Because of the special nature of the leader, recovery is usually more complicated than in the case of followers. We should also be aware of the things that can go wrong with the process. The recovery involves designating a new machine as the leader in a process called failover, that works as follows:
- The system detects if the leader has failed. This is usually done by monitoring the leader's activity. If the leader doesn't respond for a specific period (say, 10 seconds) the system assumes it's dead and starts failover.
- One of the followers is chosen and promoted to leader. Usually, it's the replica with the most up-to-date version of the data, but that's not always the case. The choice of a new leader is a form of consensus (a hot research topic in distributed systems).
- All clients must be reconfigured to send the data to the new leader.
- Followers start consuming data from the new leader.
- The old leader must be handled, as it might believe it's still the leader if it comes back online. You must ensure that it stays offline or by ensuring it comes online behaving like a follower.
The process seems simple, but many things can go wrong:
- If async replication is used, all writes that the followers haven't processed yet are lost.
- In some special circumstances two nodes can believe they are leaders. Receiving updates from two leaders can damage the data in the replicas.
- Timeout should be chosen carefully. If it's too long, more data will be lost, but if it's too short you could kickstart a complete failover in vain. Raises in load can sometimes cause the leader to lag a bit, but it's still working and no failover is needed. In that situation, starting a whole failover will put even more load on the system.
Recovery in production
We just learned the basic ideas behind system recovery. The recovery process of most implementations follow a similar outline, so you'll be able to understand what's going on when you hear the words recovery and failover in your production systems. In real systems, these processes can be performed manually by a system administrator or happen in a totally automatic fashion.
We've been talking about the replication log for a while without paying much attention to it. The stream of changes from leader to followers plays a very important role in replication. In the next article, we will learn how this works.
What to do next:
- Read the next article in this series here
- Share this article with friends and colleagues. Thank you for helping me reach people who might find this information useful.
- This series is based on Designing Data-Intensive Applications, make sure to take a look at chapters 5 and 6 for a more in-depth explanation of replication and sharding. This and other very helpful books can be found in the recommended reading list.
- Send me an email with questions, comments or suggestions (it's in the About Me page)
