
Replication is the process by which data is copied, stored and kept up-to-date across different data storage systems.
Most of the theory behind replication has existed since the '70s. With the advent of cloud computing and distributed databases, this information has become more important than ever for professional software engineers.
While it's unlikely that you will end up building the underlying mechanisms that support replication, understanding how it works is quite useful. If you develop web applications that serve large numbers of users, you will probably use some form of replication in production.
Spending time to learn how replication works is useful for backend developers. A clear understanding of the tradeoffs and risks of replication will help you design more resilient systems and also recover when things go wrong.
There is an important assumption we will make for this series of articles: all our data fits in a single machine. Spreading the data of a single database in multiple machines is called sharding, a more advanced topic in distributed DB systems.
Why do we want replication?
Let's start with a simple definition of replication:
Replication means keeping a copy of our data in many machines that are connected with each other using a network.
You might think at first that keeping the same data in several databases is a waste of resources, but there are many benefits associated with this approach:
- Improved resilience: If you have only one database and it fails, your system will stop working. On the other hand, a system with many databases can continue serving users even if individual databases crash. Data corruption also stops being a threat, as you can use healthy databases to fix the ones that have corrupted data.
- Faster response times: Keeping databases close to your end-users reduce the time it takes to serve the data. Keeping your data around the globe helps you improve the user experience for people living in different parts of the planet.
- Scaling for more users: You can serve read operations from all your databases, increasing the number of users that the system can support at a given time.
Now that we know why replication is a cool thing, let's add the first term to our glossary.
- Replica: Each node (machine) that stores a copy of the database.
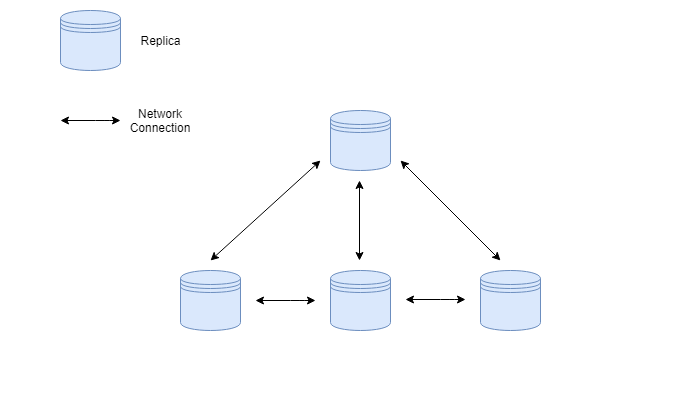
Follow the leader
We need to find a way to ensure that the data in every DB is consistent. If we allow every database to receive write requests (or any request that changes data), we would need to update every other replica in the system. A simpler way of ensuring that data stays consistent is using leader/follower replication.
In this form of replication, all writes or other operations that change data are send to the replica appointed as the leader. After performing the changes locally the leader notifies the followers about the changes in data. The followers, in response, update their own local copy of the data to keep up with the leader. You can read from any replica, but only the leader will accept writes.
In summary, leader/follower replication works as follows:
- One of the replicas is designated as the leader.
- All write requests or other requests that can change data must be sent to the leader, and only the leader. Notice that by write we mean all types of requests that could change data, including updates.
- When the leader receives a write, it performs the changes in the local data.
- After the local change is done, the leader notifies all the followers about the changes in data. This is usually sent as a replication log with all the changes in a given time window.
- The followers receive the replication log and perform the changes to their local copies of the main database. The changes are applied in the same order as they were processed by the leader.
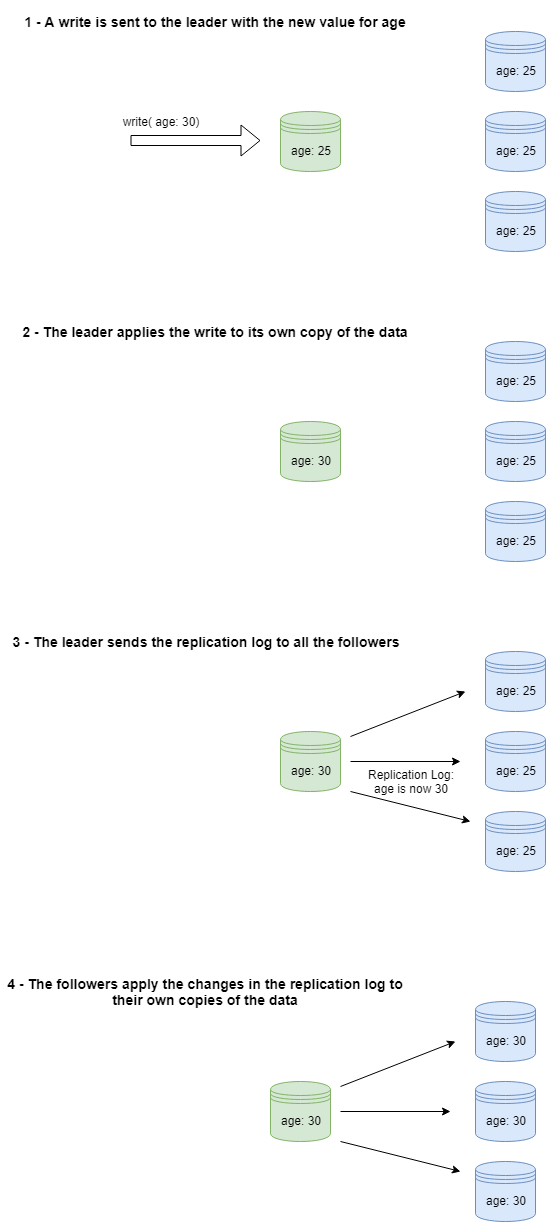
The details among different implementations of leader/follower change, but this workflow is common in most cases.
Synchronicity
There are two main types of replication: synchronous and asynchronous. The type you choose will heavily impact the dynamics between followers and leader and provide specific benefits and challenges to your system.
Synchronous replication
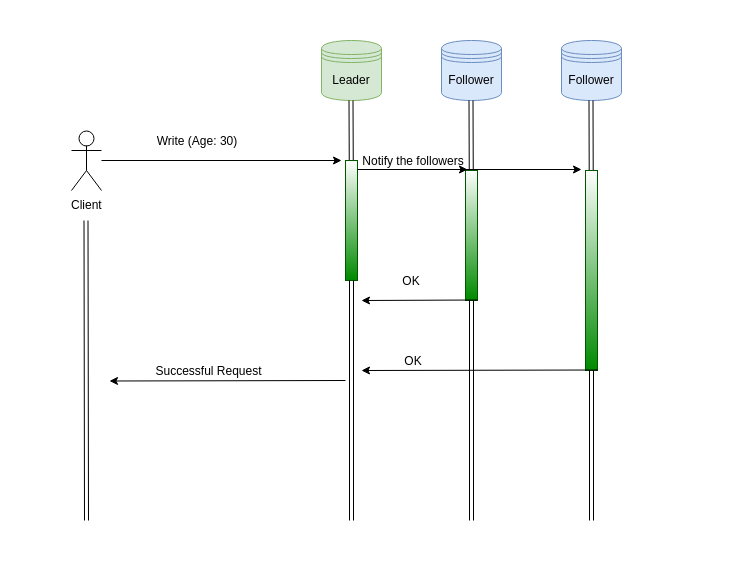
In synchronous replication, the leader waits until all the followers notify that their updates were performed correctly. The updated data is visible to the clients only after every follower gave a thumbs up.
This approach has an obvious upside: every follower will have an up-to-date copy of the data. This means we won't serve stale data to our users. Also, if the leader crashes, we are guaranteed to have copies of the latest data.
On the other hand, the downside of this approach is quite dangerous. If one of the followers malfunctions (crashes or get disconnected) the leader must block all writes until the affected replica is available again. This means that a failure in a single node halts the whole system.
Because we want to build resilient systems, synchronous replication is rarely used as the only approach for replication. Asynchronous replication is used much more often.
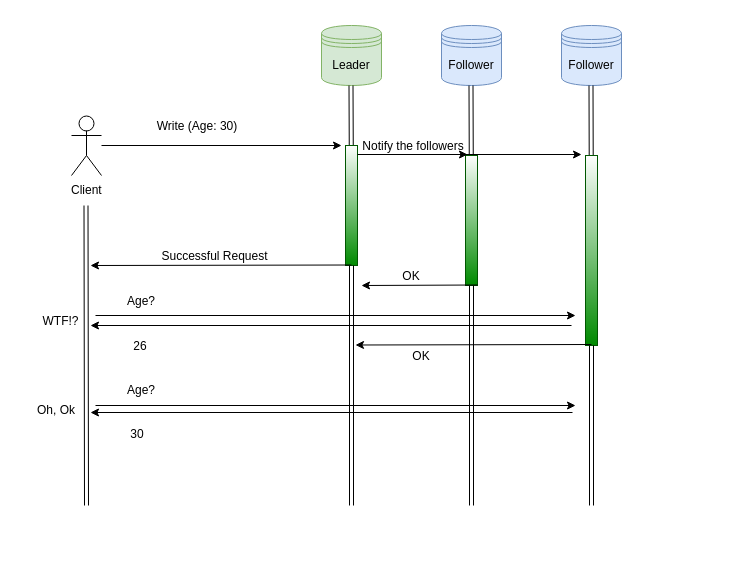
Asynchronous replication
In asynchronous replication, the leader doesn't wait for the Ok message from the followers. In this case, even if all the followers die the leader will continue processing writes and serving data. There are two things to consider when using asynchronous replication:
- The leader crashes and data is lost: If the leader crashes and the changes haven't been replicated yet, those changes will be lost.
- The followers fall behind the leader by several minutes: If your systems start to operate close to maximum capacity, there can be a significant lag between your followers and the leader. This results in followers serving old data to the users, something they might not be happy about. Replication is usually very fast, but if there is a significant load on the system they can fall behind several minutes.
Despite the downsides, fully asynchronous replicas are the most common scenario in production systems. The fact that data can fall behind some seconds is outweighed by the benefits of having replicas that don't bring down the whole system if they crash.
For most realistic production scenarios, asynchronous replication works well enough. They provide you the benefits of replication with only a small amount of risk.
Semi-syncrhonous
There is a third type of replication called semi-synchronous. In this case, all followers except for one are asynchronous. If for some reason the synchronous follower fails, you pick any of the remaining followers and make it synchronous.
What happens if individual replicas fail, do they stay dead?
Replicas will fail sooner or later.
If that happens, you need to understand and decide how the recovery of the system will be managed. There are many different recovery techniques used in production replicas, and having a basic understanding of the process will help you understand what is going on if this happens in one of your systems.
The next article will deal with recovery in replicated data systems.
What to do next:
- Read the next article in this series here
- Share this article with friends and colleagues. Thank you for helping me reach people who might find this information useful.
- This series is based on Designing Data-Intensive Applications, make sure to take a look at chapters 5 and 6 for a more in-depth explanation of replication and sharding. This and other very helpful books can be found in the recommended reading list.
- Send me an email with questions, comments or suggestions (it's in the About Me page)
