In the previous article, we learned about hot/cold learning.
We also learned that hot/cold learning has some problems: it’s slow and prone to overshoot, so we need a better way of adjusting the weights.
A better approach should take into consideration how accurate our predictions are and adjust the weights accordingly. Predictions that are way off result in big adjustments and good predictions change them just a little bit.
We need to find a way of taking into consideration the error in the prediction when calculating the adjustment factor for a weight. The first thing we’ll need is to understand how the value of a specific weight affects the resulting error.
Understanding this relationship will help us find a way to reduce the error by adjusting our network’s weights.
Learning how weight affects error
Remember the code we used to calculate errors in the previous article?
error = (predicted_value - expected_value)**2
We need to find a relation between weight and error, and this expression is a good start. Do you remember where predicted_value came from? Yes, it’s the value predicted by the neural network for a given input, calculated as:
predicted_value = input * weight
We can replace the second value in the first expression and obtain:
error = (input * weight - expected_value)**2
Or if you prefer the equation form:
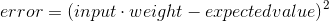
This equation explains how the value of a specific weight affects error. We already know the value of input and expected_value from our training set (the set of [input, expected_value] we use to train the network).
For this example, suppose we only have one value pair, with an input of 0.2 and an estimated value of 8.
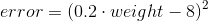
If you plot this equation, this is the result:
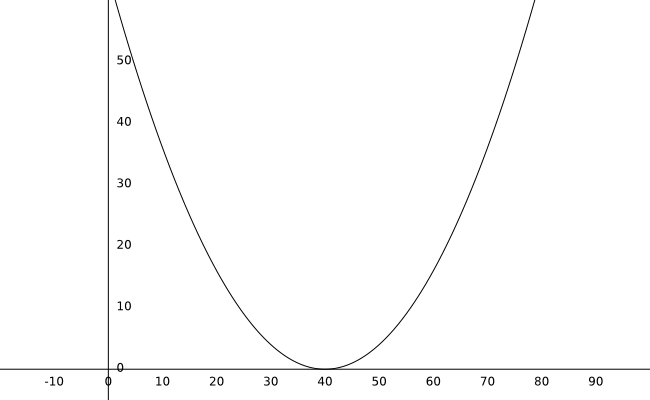
With an initial weight of 10, we can calculate the error as 36 (the red dot on the graph).
Before proceeding, we need to leverage the power of one of the most useful mathematical tools: derivatives.
How sensitive is a variable to change in another variable?
A derivative tells me how much variable changes in response to a change in another variable. This is a measure of how sensitive a variable is to changes in another one.
Strictly speaking:
The derivative of a function gives us the slope of the line tangent to the function at any point on the graph.
But we are not here for a course in calculus, all you need to know is that we can use the value of the derivative to understand the rate of change between two variables.
Remember that we are looking for a way to update the weight in proportion to the value of the error. If the weight produces a big error, we need to perform a considerable change. If we are getting an error with a value close to 0, we need just a small tweak.
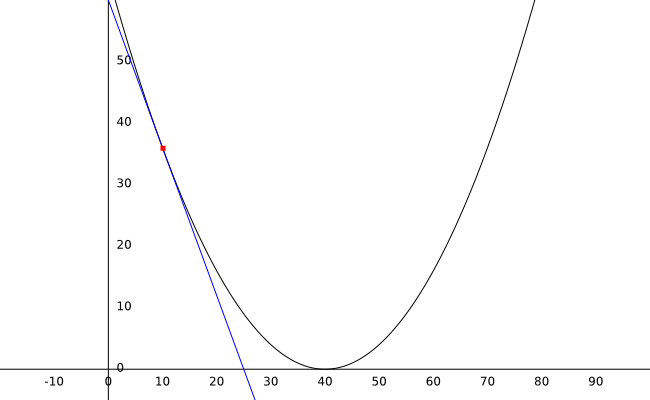
Derivatives are useful for this task because in this case, their value is proportional to how close we are to achieving the lowest possible error. The closer we get to the bottom of the curve (where the error is 0), the more parallel to the x-axis the tangent becomes and the smaller the value of the derivative.
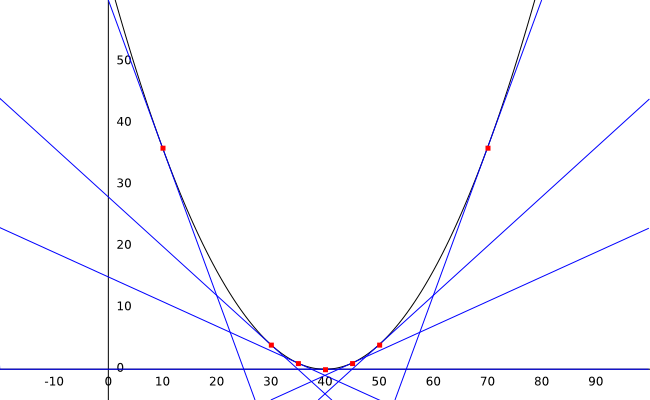
Observe the graph above and pay attention to the value of the line’s slope (the derivative) at different points.
- At weight:10 the value of the derivative is -2.4
- At weight:30 the value of the derivative is -0.8
- At weight:35 the value of the derivative is -0.4
- At weight:40 the value of the derivative is 0
- At weight:45 the value of the derivative is 0.4
- At weight:50 the value of the derivative is 0.8
- At weight:70 the value of the derivative is 2.4
Look at the tendency in the values: If our weight is at the left of the curve, the derivative’s value will be negative. If the weight is on the right side, the value of our derivative will be positive. Also, the farther we are the higher the value.
So, to summarize, a derivative tells me all this info:
- If we are far from the bottom of the curve, the value of the derivative will be big.
- If we are close to the bottom of the curve, the value of the derivative will be small.
- If the derivative is negative (we are on the left side of the curve), we need to increase the value of the weight.
- If the derivative is positive (we are on the right side of the curve), we need to decrease the value of the weight.
Let’s use this info to update our weights in a smarter way.
Implementing gradient descent in Python
The technique we will use is called gradient descent. It uses the derivative (the gradient) for descending down the slope of the curve until we reach the lowest possible error value. We will implement the algorithm step-by-step in Python.
What’s the value of our derivative?
The first thing we need is calculating the derivative. The derivative of our error equation with respect to weight is given by:
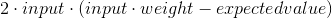
Now, this equation needs two tweaks before we can implement it, just for convenience:
- I already know that input*weight = predicted value, so I’ll use that in the equation instead.
- We will get rid of the 2 multiplying the expression. We care only about the other parts of the equation. Later we will use a special factor to scale the value of our derivative, as a result, that 2 is not needed.
The equation for the derivative we will use is:
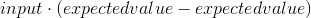
Or, in Python:
derivative = input * (predicted_value - expected_value)
Scale it using Alpha
Remember from the last article that sometimes adjustments on the value of weight can overshoot. If the tweak is too big we run the risk of running an infinite adjustment loop. If the value is too small compared to the other parameters, our learning process will be too slow.
For fixing this, we will scale the adjustment using alpha, a number that helps us regulate the learning rate and protect the code from overshooting or from going too slow. This value is chosen experimentally: try different orders of magnitude (…, 10, 1, 0.1, 0.01, 0.001, …) until you find the right one.
In python, this scaling can be implemented as:
alpha = 18
weight_adjustment = alpha * derivative
Add it or subtract it from weight?
Now that we have an adjustment factor, should we add it or subtract it from our weight?
Remember the summary we wrote above:
- If the derivative is negative (we are on the left side of the curve), we need to increase the value of the weight.
- If the derivative is positive (we are on the right side of the curve), we need to decrease the value of the weight.
So, a negative derivative value should increase weight, whereas a positive value should reduce it. This means that we should subtract it from our weight.
In Python, it would look like this:
weight -= weight_adjustment
Final implementation
Putting it all together in a complete demo, our final file has these contents:
def neural_network(input, weight):
predicted_value = input * weight
return predicted_value
input = 0.2
expected_value = 8
weight = 10
while True:
# Because of how python handles floating point, we round the values
predicted_value = round(neural_network(input, weight), 2)
print("According to my neural network, the result is {}".format(predicted_value))
error = (predicted_value - expected_value)**2
print("The error in the prediction is {} ".format(error))
derivative = input * (predicted_value - expected_value)
print("The value of our derivative at weight={} is {}".format(weight, derivative))
alpha = 18
weight_adjustment = alpha * derivative
weight -= weight_adjustment
print("The new value of our weight is {}".format(weight))
print("\n")
if(error == 0):
break
If you run this code, you will get the following results:
According to my neural network, the result is 2.0
The error in the prediction is 36.0
The value of our derivative at weight=10 is -1.2000000000000002
The new value of our weight is 31.6
According to my neural network, the result is 6.32
The error in the prediction is 2.822399999999999
The value of our derivative at weight=31.6 is -0.33599999999999997
The new value of our weight is 37.648
According to my neural network, the result is 7.53
The error in the prediction is 0.22089999999999976
The value of our derivative at weight=37.648 is -0.09399999999999996
The new value of our weight is 39.34
According to my neural network, the result is 7.87
The error in the prediction is 0.01689999999999997
The value of our derivative at weight=39.34 is -0.02599999999999998
The new value of our weight is 39.808
According to my neural network, the result is 7.96
The error in the prediction is 0.001600000000000003
The value of our derivative at weight=39.808 is -0.008000000000000007
The new value of our weight is 39.952
According to my neural network, the result is 7.99
The error in the prediction is 9.999999999999574e-05
The value of our derivative at weight=39.952 is -0.0019999999999999575
The new value of our weight is 39.988
According to my neural network, the result is 8.0
The error in the prediction is 0.0
The value of our derivative at weight=39.988 is 0.0
The new value of our weight is 39.988
You can see how the first few adjustments to the weight change the value a lot (from 10 to 31.6). You can play around with the value of alpha to see if you can speed up the learning process without causing overshot. An alpha=25, for example, produces the following output:
According to my neural network, the result is 2.0
The error in the prediction is 36.0
The value of our derivative at weight=10 is -1.2000000000000002
The new value of our weight is 38.800000000000004
According to my neural network, the result is 7.76
The error in the prediction is 0.0576000000000001
The value of our derivative at weight=38.800000000000004 is -0.04800000000000004
The new value of our weight is 39.952000000000005
According to my neural network, the result is 7.99
The error in the prediction is 9.999999999999574e-05
The value of our derivative at weight=39.952000000000005 is -0.0019999999999999575
The new value of our weight is 40.00000000000001
According to my neural network, the result is 8.0
The error in the prediction is 0.0
The value of our derivative at weight=40.00000000000001 is 0.0
The new value of our weight is 40.00000000000001
See! way faster than alpha=18. However, alpha=35 causes the correction to overshot and the code loops forever.
Key takeaways
Gradient descent is a very important concept in many ML algorithms. It might be hard to understand at first, but I hope that after reading this article it will be much clearer.
Some of the things you need to remember about this technique are:
- Derivatives tell us how much a variable changes in response to a change in another variable.
- By finding the relation between weight and error, we try to find a way to minimize the error by changing the value of the weight.
- You can use the value of the derivative to know at which side of the curve and how far from the bottom (the minimum error) you are.
- By using the derivative (scaled by alpha) you can update the value of your weight in an iterative process that will bring you closer to the minimum error.
- Choosing a good value for alpha is important: too small can result in slow learning, and too big can result in an overshot.
You can also train multiple weights
In this article, we studied a simplified version of gradient descent with only one weight. In the next article, we will explore a generalized version that will enable us to train networks with any number of inputs and outputs.
Thank you for reading!
What to do next
- Share this article with friends and colleagues. Thank you for helping me reach people who might find this information useful.
- You can find a great refresher on derivatives here.
- This article is based on the book: Grokking Deep Learning and on Deep Learning (Goodfellow, Bengio, Courville).
- You can find the source code for this series here
- Send me an email with questions, comments or suggestions (it’s in the About Me page)