
In the previous articles, we learned a definition of data science and why so many companies are investing in this field. We also learned about some of the most common scenarios where data science is the right tool for the job.
In this article (the last in the series) we will learn a basic framework for organizing the tasks in a data science project. No matter which problem you are facing, it will involve most of the steps we will discuss next.
Having a reference will help you plan a project by organizing it in stages. It's important to know that the lifecycle of most data science projects is cyclical: you will usually perform various iterations of the process to improve the quality of your models and findings. Data science projects are complex endeavors, and the information you learn on every iteration will let you improve the quality of the final product.
Common steps for crafting a data science solution
You might be trying to create a model that predicts the likelihood of churning, or trying to find segments of users with some things in common. No matter what problem you are tackling, it's always possible to divide the tasks by stages. Please note that these are not the only stages for a project, depending on your needs you might need more specialized steps. Nonetheless, having a simplified roadmap is a good way to get started.
Step 1: Define the problem
This is a crucial step in the project, so it might surprise you that many data scientists rush past (or skip) the problem definition stage. It involves clarifying the following questions:
- What is the main goal of the project?: You'll need to talk to the stakeholders to understand their needs and how data science can provide value. It's important to ask all the clarifying questions you need because your models will be useless if they solve the wrong problem.
- What type of problem am I facing?: Once you understand the needs of the stakeholders you'll be in a much better position to reframe the problem as a standard data science task. Is it a multiclass classification problem? or perhaps is a simple regression problem? Or is outlier detection the best fit for this project, or maybe we are talking about segmentation? These are the questions you need to answer before proceeding.
- What will be the input data and what am I trying to find out?: This step is crucial, as you need to define which data is needed for the project and how to get it. Sometimes the company has enough relevant data available, but in situations where this is not true, you will need to devise a plan for gathering that data. It's important to talk with domain experts, as they might provide very valuable insights into what pieces of data might be more useful and which ones might not be needed.
- What does success look like and how do I measure it?: You will need to define what success means in this particular project and how to measure it. There are different metrics you can collect for your models, and defining success will help you choose which one you need to pay more attention to. You might want to measure precision/recall, the area under a ROC curve, the RMSE or MAE, just to mention some common metrics. This choice will let you decide how to optimize the model.
Spending time in this stage is very important because the decisions you make will have a huge impact on the project. Until all these things are defined you shouldn't move forward.
It's important to remember that in the case of predictive tasks, two assumptions are made:
- The outputs can be predicted using the available inputs.
- Our data is informative enough to create a model that learns the relationship between inputs and outputs.
This hypothesis will be tested by creating and tuning different models and testing them on real data. Sometimes, the hypothesis is proven wrong because we don't have data with enough information to predict the results we need. In this case, we have two options: find better data or conclude the project.
You also need to clarify something specific to projects that try to predict the future based on historical data: the assumption that the future will behave like the past. If this assumption is not true for the variable(s) we are trying to predict, then no matter how much data we gather and how many models we train, the project will never be able to provide the results we want.
Once we discuss all the questions and find their answers, we are ready for the next stage.
Step 2: Define a validation protocol.
This step's goal is to define how you will validate the performance of your models.
You will build many different models and tweak their hyperparameters to try to find the one that gives the best results, so it's important to decide a way to validate the model. At this stage, you will set aside a subset of the data to use as a final test set, and the remaining data will be used to train and validate different models.
Two popular options for validation protocols are:
- Use a hold-out validation set: If you have lots of data for training, you can put aside a part of it to validate the models. You need to select a representative subset of the training data for the validation to be effective.

- K-fold validation: You will select k different subsets of data as validation sets and train k models on the remaining data. After that, you will evaluate the performance of the models and average their results. This technique is especially useful if you don't have that much data available for training. The following is an example when k equals 4.
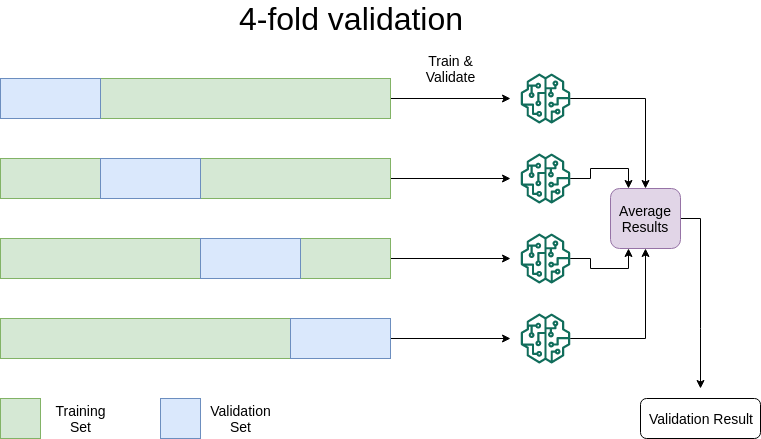
Step 3: Prepare the data
This is one of the most time-consuming tasks in most data science projects.
It's very unlikely that your data will be ready to be fed into machine learning algorithms from the beginning. Usually, you will need to aggregate together data coming from different databases or other sources. After the aggregation is done and you have a single data repository it's time to perform some transformations on the data.
Some algorithms can handle categorical data, whereas others can only work with numbers in specific formats. You might need to perform some transformations to the data available like using one-hot encoding or transforming integers to floating-point numbers. The performance of some algorithms is poor unless the inputs are in a similar range, so you will also need to scale the values within the range between 0 and 1.
Another common task is handling missing values. Some examples of your data set can have missing or wrong values, and you need to decide what to do with them or it will affect the quality of your model. You can get rid of those examples, or fill in the missing data with average values. There are many different techniques used to handle missing/wrong values, deciding which one to use depends on the specifics of the project.
This is also the stage where most feature engineering is performed with the hopes of improving the performance of the algorithms created in the next stages. A lot of time is spent in this stage, so it's important to develop good data-handling skills.
Step 4: Train your models
In this stage, we select different algorithms to build models and evaluate their performance. The most important thing is to create an initial model that beats the baseline: a model that performs better than the most naive of approaches.
For example, if you are building a model to classify photos as either oranges and apples, then the baseline to beat would be a naive model that predicts that every single photo is an orange.
If you can't find a model that beats this baseline, you'll need to go back some stages to ensure you have the right data and assumptions. If getting better data and performing some feature engineering yields no results, it might be time to reformulate the problem and find alternatives.
It's useful to train different models and compare their initial results, just to get a rough idea about how different algorithms perform on your data. After you have some models that give reasonable results, it's time to tune them!
Step 5: Tune your models
Models have hyperparameters you can tune to regulate their learning process. In this stage, you will run lots of experiments with different hyperparameter values to try to find the model that provides the best results.
You need to be careful with overfitting, which is what happens when a model learns how to perform very well on training data but does poorly on test data. This happens because your model might be learning to imitate the details of your training set, instead of generalizing more general rules.
It's useful to monitor the training and validation loss/accuracy of the models you are building to understand their behavior. Remember that this is a cyclical process: evaluate a model -> tune hyperparameters -> evaluate on validation data. You repeat this process until you get good results.
You must also be careful with overtuning your model on validation data. If your model performs great on the validation data but does poorly on test data you can be sure that your models are learning particularities of the validation set instead of general rules. Hyperparameter tuning should be done with the utmost care and using as much cross-validation as possible to ensure your models stay general enough.
Finally, after tuning the hyperparameters, it's time to test the model on the test data you set aside in previous stages. Depending on the results you can present your findings to the stakeholders or you will need to go back to previous stages.
Now repeat
Data science projects are cyclical in nature: you will repeat many of those stages several times during the course of a project. The first iteration will give you valuable information to improve the results of the following iterations. Maybe you will learn some underlying details of the data that can be used to create a better training set, or perhaps you discovered that the problem needs to be reformulated.
No matter what, running several iterations of the process will help you get closer to a product that solves the right problem in the most efficient way.
That's all, for now
And with this article, we conclude our little journey exploring the basics of data science. We learned what it is, when to use it, why use it and how it's done.
Data science is a multidisciplinary field with endless applications, and there is a place for everyone. From data analysts to machine learning engineers and statisticians, people from different disciplines can leverage their skills to produce great data products and provide valuable insights. If you are interested in the field, this is the perfect time to join the data revolution.
I hope this series has taught you something new and helped you decide if data science is the right field for you.
Thanks again for reading!
What to do next
- Share this article with friends and colleagues. Thank you for helping me reach people who might find this information useful.
- This series on the MIT Essential Knowledge series books on data science and machine learning. These and other very helpful books can be found in the recommended reading list.
- Send me an email with questions, comments or suggestions (it's in the About Me page)
