
Supervised learning is perhaps the most common form of machine learning task in use nowadays.
This form of learning makes use of a labeled training dataset to create a model that predicts a target of interest. If this line makes absolutely no sense to you, don't worry. After reading this article you will have a clear understanding of supervised learning and its two most popular applications: regression and classification.
Training machines with examples
Supervised learning is a process in which you teach a machine to predict a particular result by feeding it examples 'with the right answers'.
The first thing you need to know is what are you trying to predict. You might want to create a program that classifies pet photos as dog photos or cat photos, or a program that predicts the prices of houses in different districts in Sydney, Australia.
After deciding the variable you are trying to predict (your target), it's time to gather data examples from the real world and label them. In our first example, we would start gathering photos with dogs and photos with cats and tagging them with the right category. This photo of a puppy is a dog photo, that photo of a cat playing with a laser is a cat photo, and so on for every example.
Before the training stage, you will set aside a percentage of your training set to test the performance of your models. Afterwards, you will feed your labeled examples into an algorithm that will learn to generalize a relationship between the inputs (the photos) and the targets (dog/cat), producing a model you can use to classify fresh images it has never seen before. In this context, this is what training means: teaching a machine to perform actions learned from training data.
You can evaluate how well the model performs on your training set, the one you put aside before training. If the results are satisfying, you can deploy the model into production and use it to solve the original problem. The following diagram shows a high-level view of the supervised learning process.
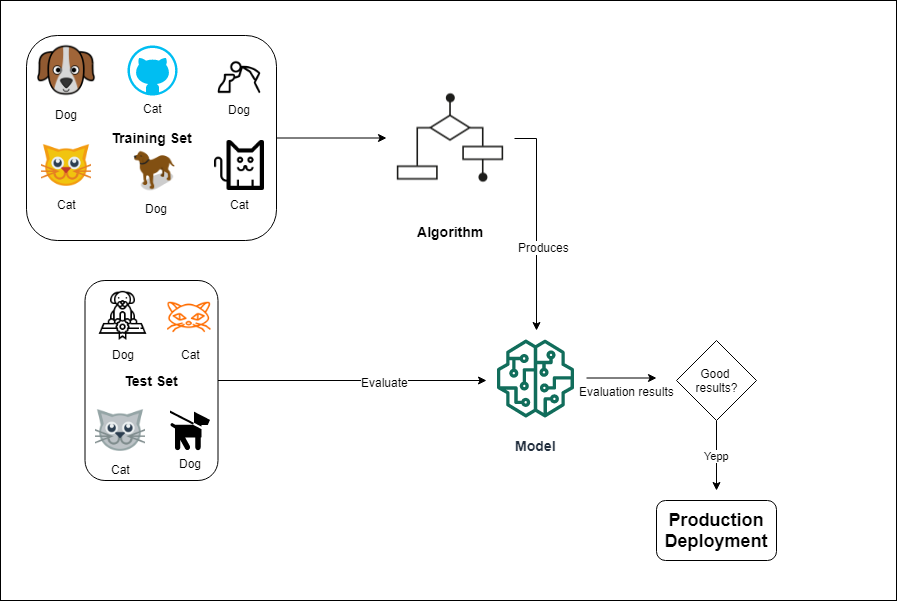
This is an example of a classification task.
Classification and regression are the most common applications of supervised learning. If you are interested in a career in machine learning you will likely spend most of your time creating these types of models, so let's take a look at them.
Classifying the world
A classifier is a model that tells you the class(category) an instance of your data belongs to. In the previous example, our instances were photos of pets, and the classes were cat photos and dog photos.
The training set for classification tasks is usually a collection of instances (individual instances of the phenomenon you are trying to model) with a label that specifies the class they belong to.
Classifiers can be further classified ( ͡° ͜ʖ ͡° ) into different subtypes depending on the number of target classes (binary or multiclass) and how many categories an instance can belong to at the same time (single-label and multi-label), let's take a look at those.
Binary classifiers
A binary classifier is a model that classifies examples into two possible classes. Classifiers are capable of telling you if an email is either spam or not spam, if a photo of a face is happy or sad or if a substance is harmless or dangerous.
The most common setup for binary classification is to have a positive class (class) and a negative class (not-class). In this sense, you can re-define the previous examples as spam/not-spam, happy/not-happy and dangerous/not-dangerous.
Some types of binary classifiers don't just tell you a result, but they also provide you a probability that the instance you are classifying belongs to the predicted class.
Binary classifiers are some of the most studied and used models in machine learning, and many other models build on top of them (like some forms of multiclass classifiers).

Multiclass classifiers
As you might imagine from the title, a multiclass classifier is a model that classifies instances into many categories. Like in the previous case you can get the results as the probability of belonging to a particular class.
It's important to note that there is a difference depending on the number of classes an instance can belong to at the same time.
If the classes are mutually exclusive (an object can only belong to one class at a time) you are building a single-label multiclass classifier. If an instance can belong to more than 1 class at the same time then you need a multi-label classifier.
Depending on the particular scenario, your choice of algorithms and evaluation methods will differ.
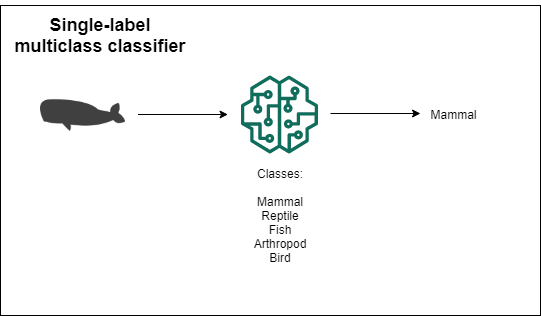
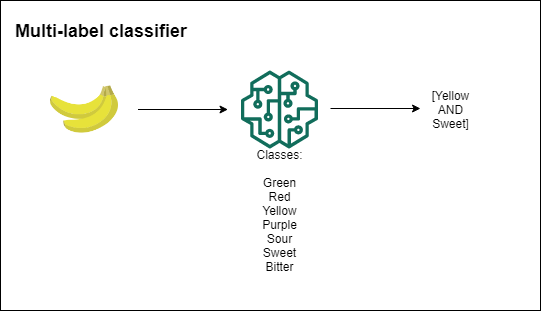
Regression
The goal of a regression model is to predict a continuous value. The training set for a regression problem is usually a collection of instances with the associated numeric value you are trying to predict.
The following are some examples of regression problems
- Predict the price of houses in Amsterdam given the size of the house (in square meters), the year the house was built, the average income of the area in which the house is located, the number of bedrooms and the color of the mailbox.
- Predict a person's likelihood developing diabetes given the height, weight, number of cigarettes smoked per day, average caloric intake, average hours of physical activity per week and amount of carbs consumed per day.
- Predict the stock price of a company one year from now based on the number of Disney films released last year, the color of underwear the CEO wears with more frequency and the title of his/her aunt's favorite song.
Regression tasks are extremely common in machine learning. If you decide to pursue a career in data science or ML engineering, many of the models you'll build are likely aimed to solve regression problems.

The core assumption of supervised learning
Ok, now you have an idea of what supervised learning is and how the process works. In brief, you collect a lot of data relevant to the problem you are trying to solve and label it with the correct answers, or the expected result your model is trying to predict. Then, all this training data is fed into an algorithm that will generate a model that maps the inputs into classes(classification) or values(regression).
For this process to work, the information contained in the training set needs to have enough predictive power for the algorithm to find a correlation between the two sets.
For example, if you want to predict the likelihood a given person has to develop diabetes, you might want data like the BMI, genetic predisposition and dietary habits. All 3 with powerful correlation with the variable you are trying to find (likelihood to develop a disease, in this case). Other data, like favorite film, shoe size, and favorite headphone brand has less predictive power for this particular target, so it makes little sense to add it to the training set.
Sometimes, the data gathered doesn't provide enough information to build a model that performs well, in this scenario you need to reformulate the problem or find data with better quality.
Supervised learning is a huge topic with lots of important concepts. The goal of this article was to present a high-level view of the topic. Hopefully, by now you have a better understanding of supervised learning, and we will be prepared to dig deeper in more elaborate topics in future articles.
Thank you for reading!
What to do next
- Share this article with friends and colleagues. Thank you for helping me reach people who might find this information useful.
- This article is based on Data Science for Business: What You Need to Know about Data Mining and Data-Analytic Thinking. This and other very helpful books can be found in the recommended reading list.
- Send me an email with questions, comments or suggestions (it's in the About Me page)
