
MAE and RMSE are some of the most common error metrics for regression problems.
Despite being used for the same task (understanding the errors in your predictions) there are important differences between the two. Choosing the right metrics for your model can make a huge difference in your ability to solve a problem.
The algorithms you'll use to create models use the error metric to perform optimizations. Your choice of error metric will affect the final model and the way you evaluate its performance, so it's important to understand the difference between error metrics.
MAE and RMSE are both extremely common in practice, that's why we will talk about them in this article. Before starting, let's have a quick recap:
A regression model is a model that predicts a continuous value. The most common way of training a regression model is using supervised learning: you have a set of examples with the 'right answers'. You use this training set to teach the model how to produce those answers with a set of inputs in the hopes of finding general rules you can apply outside of the training set.
Mean Absolute Error (MAE)
The mean absolute error (MAE) is defined as the sum of the absolute value of the differences between all the expected values and predicted values, divided by the total number of predictions. In equation form, it looks like this:
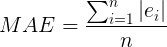
The expected values are the answers you already know that are part of the training, validation or test sets, and the predicted values are the results predicted by the model for such inputs.
For example, suppose you run your model on a validation set and get the following result:
| Expected value | Predicted Value |
|---|---|
| 5 | 10 |
| 11 | 19 |
| 37 | 32 |
| 9 | 9 |
| 21 | 30 |
| 48 | 43 |
| 33 | 21 |
| 25 | 22 |
| 12 | 15 |
Each row in the table represents a prediction and its associated expected value.
For example, in the first prediction, the right answer is 5, but our model predicted a 10, the prediction is off by 5. In the third prediction, our model predicted a 32, where the right answer is 37, the prediction is off by -5.
You can summarize this in another table with the results of the error for each prediction.
| Expected value | Predicted Value | Error |
|---|---|---|
| 5 | 10 | 5 |
| 11 | 19 | 8 |
| 37 | 32 | -5 |
| 9 | 9 | 0 |
| 21 | 30 | 9 |
| 48 | 43 | -5 |
| 33 | 21 | -12 |
| 25 | 22 | -3 |
| 12 | 15 | 3 |
How do we calculate the mean absolute error?
Easy, just average the absolute value of the errors. With the data of our table, it would be like this:
MAE = (|5|+|8|+|-5|+|0|+|9|+|-5|+|-12|+|-3|+|3|)/9 = (5+8+5+0+9+5+12+3+3)/9 = 50/9 =~ 5.55
You might be wondering why we use absolute values. This is important to take into consideration the fact that we have two types of errors:
- The predicted value is lower than the expected value.
- The predicted value is higher than the expected value.
The absolute value ensures that both types contribute to the overall error. Without it, the positive and negative errors would cancel each other. This is bad: your regression model might perform terribly and still return a very low overall error.
To illustrate this point, repeat the calculation for total error using the data in the table, but this time don't use the absolute values:
Total Error = (5 + 8+ -5 + 0 + 9 + -5 + -12 + -3 + 3)/9 = 0
Yes, a total value of 0 despite making several mistakes.
MAE is a very simple and useful metric for error, and now you know almost everything there is to know about it.
Let's talk about RMSE.
Root-Mean Square Error (RMSE)
RMSE is defined as the square root of the average of the squared errors. In equation form, it looks like this:
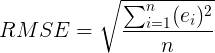
Don't worry if that sounds a bit confusing, it's much easier to understand with an example. Let's calculate it, step by step, using the same error table from before.
- Step 1: Square the error values
| Error | Squared Error |
|---|---|
| 5 | 25 |
| 8 | 64 |
| -5 | 25 |
| 0 | 0 |
| 9 | 81 |
| -5 | 25 |
| -12 | 144 |
| -3 | 9 |
| 3 | 9 |
- Step 2: Sum the squared errors and divide the result by the number of examples (calculate the average)
MSE = (25 + 64 + 25 + 0 + 81 + 25 + 144 + 9 + 9)/9 =~ 42.44
- Step 3: Calculate the square root of the average
RMSE = square_root(42.44) =~ 6.51
Calculating both the MAE and RMSE is quite simple, and both summarize the total error as a single number. Now that we know how to calculate both, let's discuss their main differences and when to use each one.
MAE or RMSE?
First, let's list the things they both have in common:
- Both are used to measure the error produced by a predictive model.
- Both are quick and easy to calculate.
- Both summarize the error as a single numeric value that is easy to understand.
The main difference between the two metrics is the contribution of individual error values to the final result.
In the case of MAE, the contribution follows a linear behavior. This means that an error of 10 contributes twice as much as an error of 5. An error of 1000 contributes 10 times as much as an error of 100.
RMSE has a different behavior: due to the squaring operation, very small values ( between 0 and 1) become even smaller, and larger values become even larger. This means that big error values are magnified, whereas small ones are ignored.
If you were to plot the contribution of single values to the error in our example, MAE and RMSE would follow a behavior like the following:
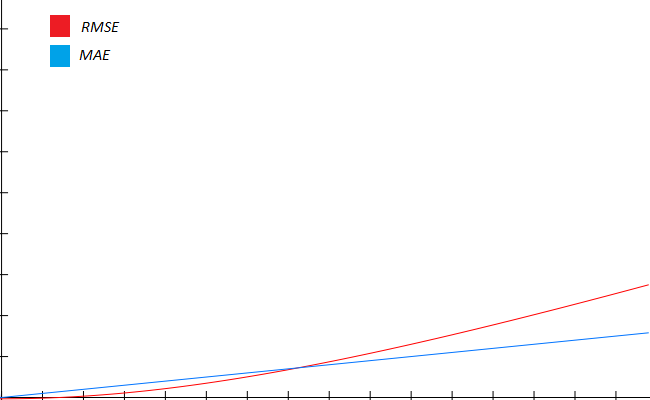
In brief, you want to use MAE for problems where the error gets worse linearly, like a model that predicts monetary loss. An error of $100 is twice as bad as an error of $50. MAE doesn't have a predilection for small errors or big errors.
RMSE is used when small errors can be safely ignored and big errors must be penalized and reduced as much as possible. RMSE gives much more importance to large errors, so models will try to minimize these as much as possible.
MAE and RMSE are both very simple and important concepts, and now you are another step ahead in your data science literacy.
I hope this information will be useful in your professional life.
Thanks for reading!
What to do next
- Share this article with friends and colleagues. Thank you for helping me reach people who might find this information useful.
- This article is based on Data Science for Business: What You Need to Know about Data Mining and Data-Analytic Thinking. This and other very helpful books can be found in the recommended reading list.
- Send me an email with questions, comments or suggestions (it's in the About Me page)
