Categorical data is extremely common in most real-world machine learning applications. The main problem is that most algorithms don't really know how to manage categorical data: they are really good at working with numbers but don't really understand the concept of category. Because of this, it's important to have a way to convert categorical data into a format most algorithms can work with.
One-hot encoding is a very simple and popular way of managing categories. In simple terms, it encodes categorical attributes as either 1's or 0's in vectors that represent the classes themselves.
Nowadays most data science toolkits let you perform one-hot encoding in very simple ways. We will take a look at the concept and then create our own implementation for encoding class attributes that we can feed into ML algorithms.
When should you use one-hot encoding
Commonly, some attributes of the data you are working with are categorical in nature.
Imagine you have a table with data about different types of pastry. As attributes, you have things like the name of the pastry, the prices in euros, the amount of sugar in grams and the size.
This last attribute is categorical, and can take the values of small, medium and big. The following table illustrates a hypotetical sample:
| Name | Price(euros) | Sugar(g) | Size |
|---|---|---|---|
| Cake_1 | 4.2 | 30 | Big |
| Cake_2 | 3.8 | 17 | Med |
| Cake_3 | 1.2 | 22 | Big |
| Cake_4 | 3 | 16 | Med |
| Cake_5 | 0.7 | 8 | Small |
| Cake_6 | 4 | 28 | Med |
| Cake_7 | 1.8 | 15 | Big |
| Cake_8 | 2.2 | 15 | Big |
| Cake_9 | 0.5 | 7 | Small |
| Cake_10 | 3 | 21 | Small |
As it is right now, you would have trouble feeding this data into most ML algorithms. They would have no problem handling values like the price and sugar content, but wouldn't know what to do with the size.
Sometimes, categorical data has a logical progression you can use to solve this issue. Size, for example, can be easily transformed to numerical values: you can say that a medium cake is 4 times bigger than a small one, and a big one 12 times bigger. If you choose 1 as the base value for small, you can easily transform the table into the following one:
| Name | Price(euros) | Sugar(g) | Size |
|---|---|---|---|
| Cake_1 | 4.2 | 30 | 12 |
| Cake_2 | 3.8 | 17 | 4 |
| Cake_3 | 1.2 | 22 | 12 |
| Cake_4 | 3 | 16 | 4 |
| Cake_5 | 0.7 | 8 | 1 |
| Cake_6 | 4 | 28 | 4 |
| Cake_7 | 1.8 | 15 | 12 |
| Cake_8 | 2.2 | 15 | 12 |
| Cake_9 | 0.5 | 7 | 1 |
| Cake_10 | 3 | 21 | 1 |
These numbers are just for illustration, their values depend on the domain problem.
Now, what happens if data doesn't have a clear numerical relation between categories? In our previous example, it was very easy because big > medium > small, so it's reasonable to replace the values with integers as long as they make sense. But what if the variable is something like colors? You can't say, for example, that red equals three times blue.
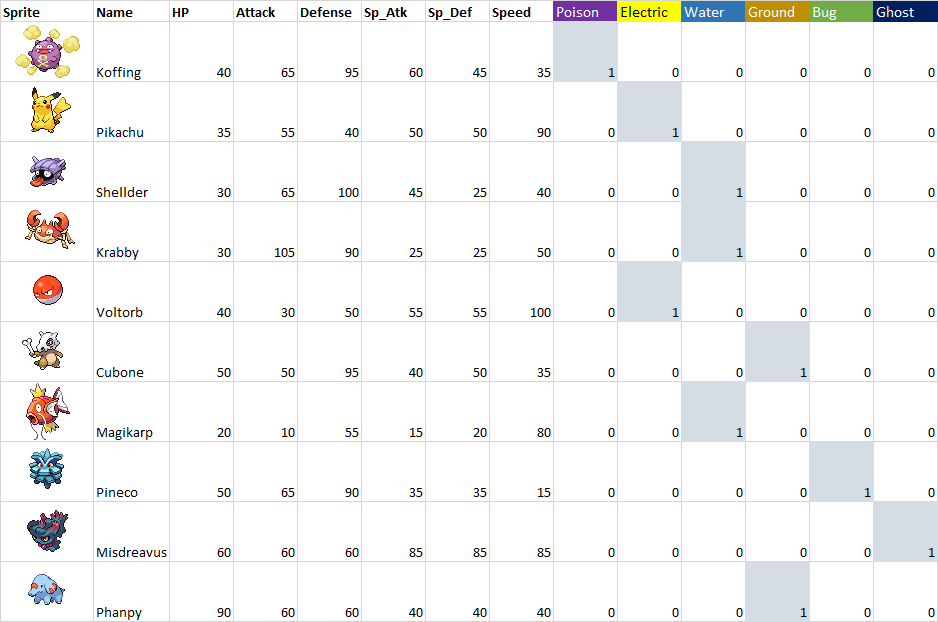
This is when one-hot encoding becomes useful. It lets you represent this sort of categorical data in a way that most algorithms can manage. For explaining how it works, let's look at the following table with some basic information about 10 pokemon (yes, we are dealing with poke data).
You can notice that attributes like HP, Attack,..., Speed are easy to handle, they are all integers. On the other hand, the Type attribute needs to be handled to be used.
Type is obviously categorical: a pokemon can belong to different type categories. It's also obvious that you can't make a replacement as in the case of pastry sizes. If you say that Poison = 2x Electric = 5.5x Water, the algorithm will learn this hierarchy even if it doesn't make any sense in real life.
This is a case where we can use one-hot encoding to transform the Type attribute in an algorithm-friendly format.
One-hot encoding works as follows:
- You will create one new column for every single category the data can take. In our case, we will need 6 new columns: Poison, Electric, Water, Ground, Bug, and Ghost.
- On every row (pokemon) you will place a 1 if it belongs to the category and a 0 if it doesn't. For the first example (Koffing), you will put a 1 on Poison and 0s on the rest of the types.
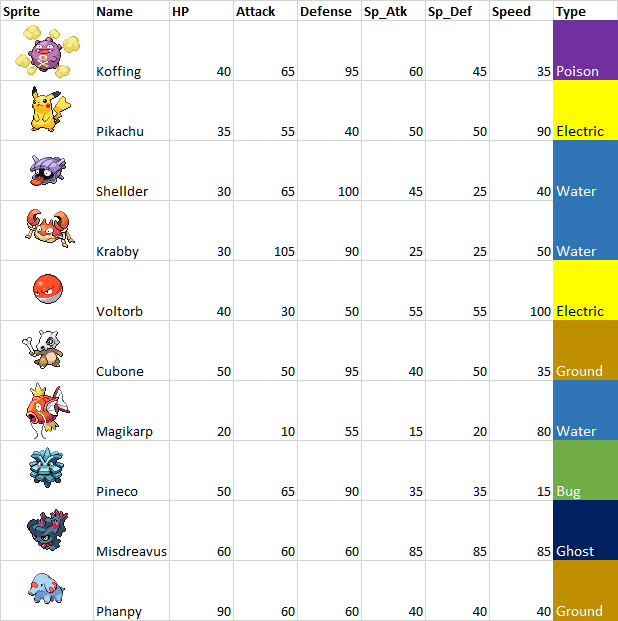
You can see the results of applying one-hot encoding to the type attribute in the following table. I grayed out the cells with a 1 to make it easier to read.
Type is now encoded vectors of 1s and 0s (which algorithms like neural networks love!).
Now that you understand one-hot encoding from a conceptual angle, let's write our own implementation using Python to get some practical experience.
One-hot encoding in Python
All the code in this section is available as a Jupyter notebook. You can find a link to the repo in the What to do next section at the end of the article.
We will transform the Type column into a one-hot-encoded representation using two approaches. The first one will be a step-by-step approach that will help you understand the encoding process, while the second one makes use of a built-in function that encodes a categorical column in a single line of code.
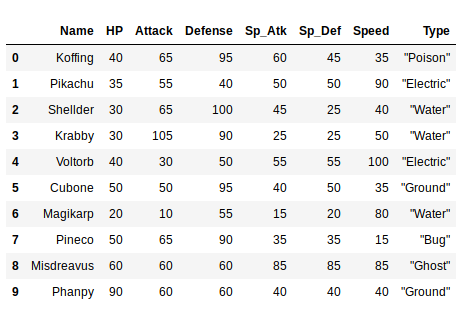
The first thing we need is to load our data in a format we can easily work with. As a first step, we will create a Pandas DataFrame with the Pokemon data:
import pandas as pd
poke_data = pd.read_csv('./poke_data.csv')
poke_data.head(10)
We can easily access the Type information and put it on a list with this:
type_data = poke_data["Type"].to_list()
type_data
>[' "Poison"',
' "Electric"',
' "Water"',
' "Water"',
' "Electric"',
' "Ground"',
' "Water"',
' "Bug"',
' "Ghost"',
' "Ground"']
Now, we will write a small python function that takes a list of categories and creates a Pandas dataframe with the one-hot encoded version of it.
We will use a NumPy matrix as an intermediate data structure. The code is commented and explained in a section-by-section fashion, so it should be easy to understand:
import numpy as np
def strings_to_onehot(categories_column):
# First, we will build a list containing the categories
# for that, we create an array with the unique elements
unique_categories = list(set(categories_column))
# We will create a one-hot matrix, the first step is to create a zero-matrix
# of dimmensions number of datapoints X number of categories
one_hot_matrix = np.zeros( (len(categories_column), len(unique_categories)), dtype=int )
# This loop sets to 1 the right slot in each row for every example in our data
for row, category in zip(one_hot_matrix, categories_column):
category_index = unique_categories.index(category)
row[category_index] = 1
# Now, let's build and return a DataFrame with the values
return pd.DataFrame(columns = unique_categories, data = one_hot_matrix)
# onehot_types is the DataFrame with the categories in one-hot encoding
onehot_types = strings_to_onehot(type_data)
onehot_types
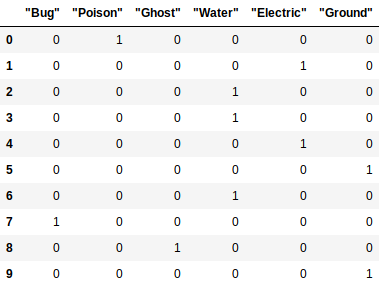
You can see that the dataframe follows the original order: the first line is for Koffing (hence, the type is Poison), the second is for Pikachu (Electric) and so on.
Now, we can join this DataFrame with the original data to obtain a new one with the type encoded as a one-hot matrix. This can be easily achieved with the following lines:
# Now we will concatenate both pieces of data
final_pokedata = pd.concat([poke_data, onehot_types],axis=1)
final_pokedata
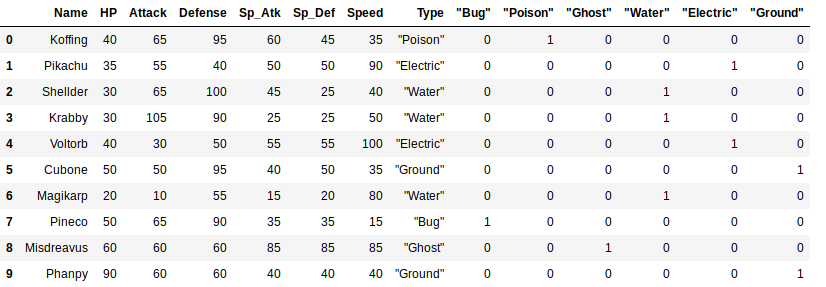
Normally, the original Type column is dropped, but in this case, we leave it there for completeness.
Cool, but isn't there an easier way of encoding categorical attributes? Yes, you could use Pandas' get_dummies function and get the same result:
poke_data = pd.read_csv('./poke_data.csv')
onehot_types = pd.get_dummies(poke_data['Type'])
poke_data = poke_data.join( onehot_types )
poke_data
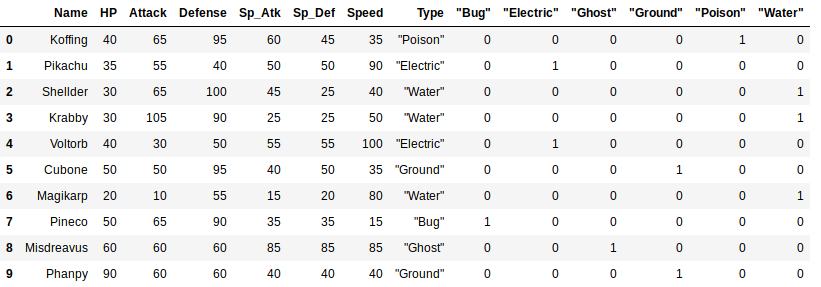
There are many other ways of transforming a column with categorical data in a one-hot representation. Because you are probably already using Pandas, managing categorical data will be very easy from now on.
Disadvantages of one-hot encoding
The most obvious disadvantage of one-hot encoding is that it makes the dataframe much bigger than it needs to be.
In our example, we dealt with just 6 new categories, which means that each row will grow by 6 attributes, not much of a problem. Real data, though, can have many more categories, and if you have several millions of rows, the impact in storage can be significant.
This is especially problematic in NLP. In a vocabulary containing just 10.000 words, you would represent each word as a vector with a size of 10.000 with a 1 in the right index. This means that even a medium-sized dataset consisting of a few hundred books can end up consuming terabytes of storage if represented using one-hot encoding.
Despite the problems, one hot encoding is a practical solution in a vast number of problems, and it's likely the first thing you will try when dealing with categorical data.
Now you know the basics of this useful technique, so go and build something interesting using data with categorical attributes!
Thanks for reading.
Legal footnote, because lawyers: All the Pokemon names, sprites, and related material belong to their respective owners. This article made use of them in a purely educational basis and thus does not infringe the copyright. Please don't sue me Nintendo.
What to do next
- Share this article with friends and colleagues. Thank you for helping me reach people who might find this information useful.
- Here you will find a repo with the code for this article.
- This article is based on Data Science for Business: What You Need to Know about Data Mining and Data-Analytic Thinking. This and other very helpful books can be found in the recommended reading list.
- Send me an email with questions, comments or suggestions (it's in the About Me page)
