Overfitting is an important concept all data professionals need to deal with sooner or later, especially if you are tasked with building models. A good understanding of this phenomenon will let you identify it and fix it, helping you create better models and solutions.
In brief, overfitting happens when your models fail to learn only the most important general patterns hidden within your data. A very powerful model can learn even the patterns that exist only in your training set. When these models are used on real data, their results are usually sub-optimal, so it's important to detect overfitting during training and take action as soon as possible.
In this article, we will discuss how to spot and fix overfitting issues.
If you look hard enough, you will find patterns
We will discuss overfitting in the context of supervised learning, which is the most common scenario.
As you might remember, in supervised learning you use training data to teach a model how to do something. Some of the most common tasks are regression and classification, which we discussed in a previous article.
Also, you might remember that we set aside two other important datasets before the training step: the validation and training sets. This data will be used to evaluate the performance of the model.
You use the training alongside different algorithms to create models in the hopes of finding specific trends or patterns that generalize well on real data. If the model fails to find enough useful patterns, it won't have enough predictive power to be useful in practice. A model that fails to capture the underlying patterns and structure of the data is said to be underfitting.
You can solve this problem by increasing the complexity of the model or finding more meaningful data. More powerful models can find subtler patterns in data, and for many problems, this is necessary to avoid overfitting. The main problem is that the training set can have specific quirks or patterns that don't exist in real-world examples of your problem.
A model that looks for patterns in a very aggressive fashion can end up learning these quirks and reduce their performance on real examples. When models learn too many of these patterns, they are said to be overfitting. An overfitting model performs very well on the data used to train it but performs poorly on data it hasn't seen before.
The process of training a model is about striking a balance between underfitting and overfitting. Because models can't differentiate between patterns that only exist in the training set and patterns that generalize well, it's your responsibility to regulate the learning process. If you use a very weak model you risk underfitting, but if you use a very powerful one you can overfit.
A real life example: presidential elections
One of my favorite examples for illustrating the idea of overfitting is the following comic made by Randall Munroe:

This comic represents a series of patterns in presidential elections that were true but didn't provide any meaningful predictive power for the task of predicting the next U.S president.
A predictive model that takes into consideration these patterns would perform poorly. The model would believe they represent significant trends and learn to spot them for making predictions. Things like No one with two middle names have become president are true in the dataset, but have little or no relation with the real problem being solved.
A real-world dataset can have similar quirks or patterns due to lots of reasons. It's important to understand that the fact that patterns exist doesn't mean they provide meaningful information for our tasks. An algorithm can't make this distinction by itself, so it's up to us to help them find the patterns that generalize well.
Ideally, your model would only learn meaningful patterns that let you predict or classify instances it hasn't seen before.
So, in practice, how can we spot overfitting?
Finding out if your model overfits
A model that overfits performs very well on the data it's been trained with, but worse on data it hasn't seen before. The best way of finding out if your model is overfitting is by evaluating its performance on both the training and validation sets. This is much easier to see with an example:
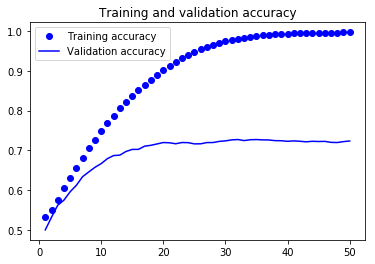
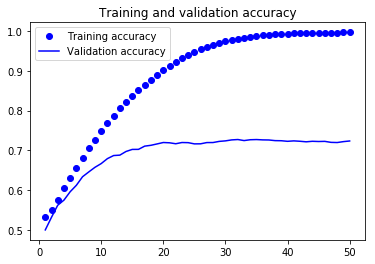
The previous graph represents the accuracy results of an image classifier built with Keras. On the X-axis you see the number of epochs (training cycles) and on the Y-axis the accuracy of the classifier.
After every epoch, the classifier learns deeper patterns in the data. You can notice an interesting tendency:
- As more epochs pass, the performance on the training set improves. This happens because the classifier learns more intricacies of the training set and can perform better predictions.
- As more epochs pass, the classifier performs better on the validation set. This happens because it learns general patterns that apply well to data it hasn't seen yet. After a specific point (around 20 epochs), the performance on the validation set ceases to improve. This is the result of learning to reproduce idiosyncrasies in the training set that don't generalize well. After this point, we see that the model is overfitting.
The easiest way to find out if your model is overfitting is by measuring its performance on your training and validation sets. If your model performs much better with training data than with validation data, you are overfitting.
Now that you know how to spot overfitting, let's talk about how to fix it.
Dealing with overfitting
There are several ways of dealing with overfitting. Which technique is more effective depends on your task, data, and algorithms, but that doesn't mean you can apply only one of them.
All the techniques used to reduce overfitting are centered around a single idea: increase the influence of patterns that generalize well and reduce the influence of less meaningful patterns. Let's explore 4 of the most common ways of achieving this:
1. Get more data
Getting more data is usually one of the most effective ways of fighting overfitting. Having more quality data reduces the influence of quirky patterns in your training set, and puts it closer to the distribution of the data in the real worlds.
Sometimes, finding data is not easy, so you need to see it as an investment, as you might need to spend time and money to get it. In this sense, it's better to see data as an asset, and not as a natural resource you can just grab.
2. Regularization
Regularization is a set of techniques used to reduce the model's capacity to learn complex patterns. These techniques usually shrink the hypothesis space of the model by reducing its complexity, ensuring that it learns mostly general patterns.
The techniques are usually model specific. For example, in a tree-like model, you would reduce the depth of the tree or the total number of leaves. In neural networks, you can reduce the number of trainable weights or layers, or insert dropout layers at different parts of the network.
Another way of applying regularization is by training different models of varying complexities and comparing their performance and how strongly they overfit.
3. Early stopping
Stopping the learning process halfway can ensure the model learns just enough information about the training set to perform well but not overfit.
In the previous Keras classifier example, we see how our network starts to overfit after around 20 epochs.
A way to ensure the network doesn't overfit is to stop the training when we reach the number of epochs when the network overfits. This is a simple (yet effective) solution for overfitting, and it applies to other algorithms.
4. Ensemble models
Ensemble models are collections of smaller models whose results are averaged for making predictions. They are very good at resisting overfitting, as they distribute errors among sub-models of different complexities.
You can think of ensembles as groups of experts whose opinion you average for reaching a general consensus. This is one of the reasons ensemble models gained lots of popularity in the last years.
Random Forest (and its variants) is one of the most popular forms of ensemble models, and it's widely applied to lots of different problems with usually very good results.
There are lots of other techniques you can use, but these four represent the most common ways of dealing with overfitting. The best way of learning how to use these techniques is by applying them on real projects using your favorite ML libraries and tools.
What you need to remember about overfitting
Overfitting is an extremely important topic for any professional data scientist or machine learning engineer, but it can be a bit daunting in the beginning. This is a summary of the most important ideas you need to remember:
- Patterns exist in your training dataset. Some of these patterns represent real tendencies in the problem space, while others are just quirks of your training set. Failing to learn meaningful patterns results in underfitting, and learning too many of the quirky patterns results in overfitting. Both scenarios lead to models that perform poorly on real data.
- Training a model is about balancing two competing forces: underfitting and overfitting. You want to learn patterns from your training set, but only the ones that generalize well. The dividing line is impossible to calculate theoretically, so lots of experimentation is needed to find the right compromise.
- You can easily spot overfitting by comparing the performance metrics of running your model when against the validation set and the training set. A model that performs much better on the training data than on the validation data is overfitting.
- There are lots of techniques used for dealing with overfitting. Usually, you increase the amount of data available or reduce the models learning power. A model that looks too hard for patterns is likely to end up learning unimportant quirks.
If you keep these things in mind when training your models it will be much easier to spot and fix overfitting.
Thank you for reading!
What to do next
- Share this article with friends and colleagues. Thank you for helping me reach people who might find this information useful.
- This article is based on Data Science for Business: What You Need to Know about Data Mining and Data-Analytic Thinking. This and other very helpful books can be found in the recommended reading list.
- Send me an email with questions, comments or suggestions (it's in the About Me page)
